DB connection遅延とConnection Pool
この文書では、代表的なアプリケーション性能障害タイプの一つであるDB連結遅延(DBC遅延)とConnection Poolの相関関係をモニタリングの観点から紹介しようと思います。
まずダッシュボードのヒットマップウィジェットを通じて一次的に障害状況を認知したと仮定した後分析メニュー下位のヒットマップメニューに移動し、時間を特定する方法で障害状況の前後を見てみましょう。 これをもとにトレース情報ウィンドウとメトリクスチャートなどを通じて障害原因を推論する過程を案内します。
事前準備
アプリケーションダッシュボード → ヒットマップ·トランザクション → トレース情報 → メトリクスチャート
-
問題現象を認知した場合は、過去の記録を照会して障害現象時点の前後を照会します。 ヒットマップトランザクションチャートでトランザクション過負荷パターンを確認した後TXトレース一覧により、トランザクション遅延の原因をDB接続の問題として予想できます。
-
区間別照会後、トレース分析を通じて詳細な遂行履歴をステップ別に確認します。 経過最も時間をかけているのがDBCステップであることが確認できます。
-
メトリクスチャートを通じて様々な指標を一緒に見ていきます。 DB Pool数チャートとDB Active数チャートを比較して、DB Connection Poolの不足が原因であることが特定できます。
-
ユーザーの運用環境に応じてConnection Poolの大きさを徐々に調節したり、リーク防止のために最適化設定をする方法が活用できます。
ヒットマップ異常パターン検出
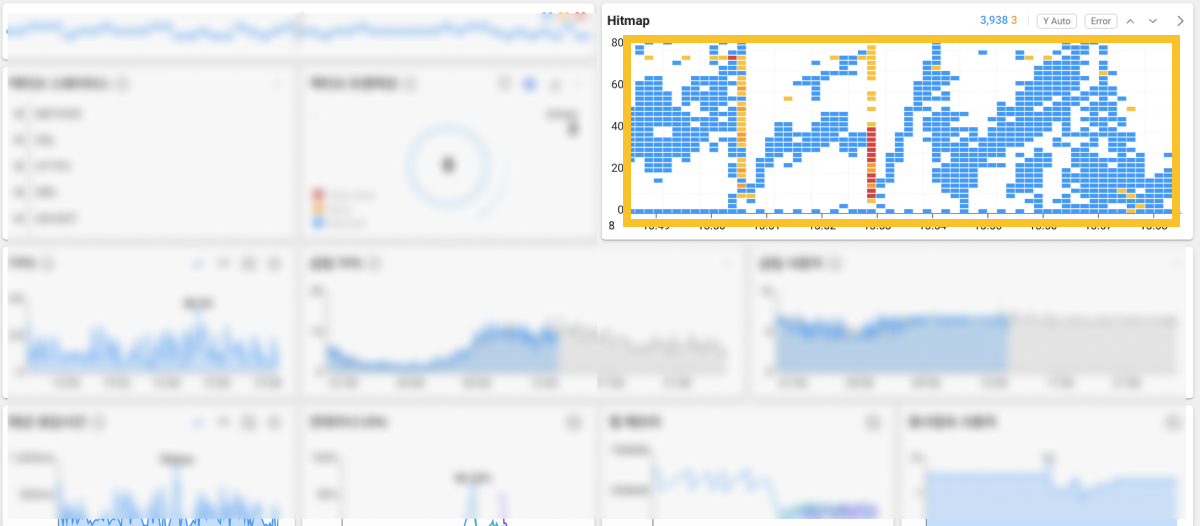
障害現象を認知し、一次的な分析を通じて障害原因を追跡する過程は、迅速さが核心です。 WhaTapは、直観的なビューを提供するだけでなく、根本的な原因を追跡するための追加情報を確保できるよう、過去記録の照会機能も提供します。 アプリケーションダッシュボードのヒットマップウィジェットで例のように急激な異常兆候を感知した場合、次の手順は何でしょうか。
ヒットマップウィジェットで問題区間をドラッグしてトランザクショントレース分析を迅速に進めることもでき、または分析メニュー下位のヒットマップに移動して、時間範囲をより広く特定する方法で前後の状況を確認することもできます。
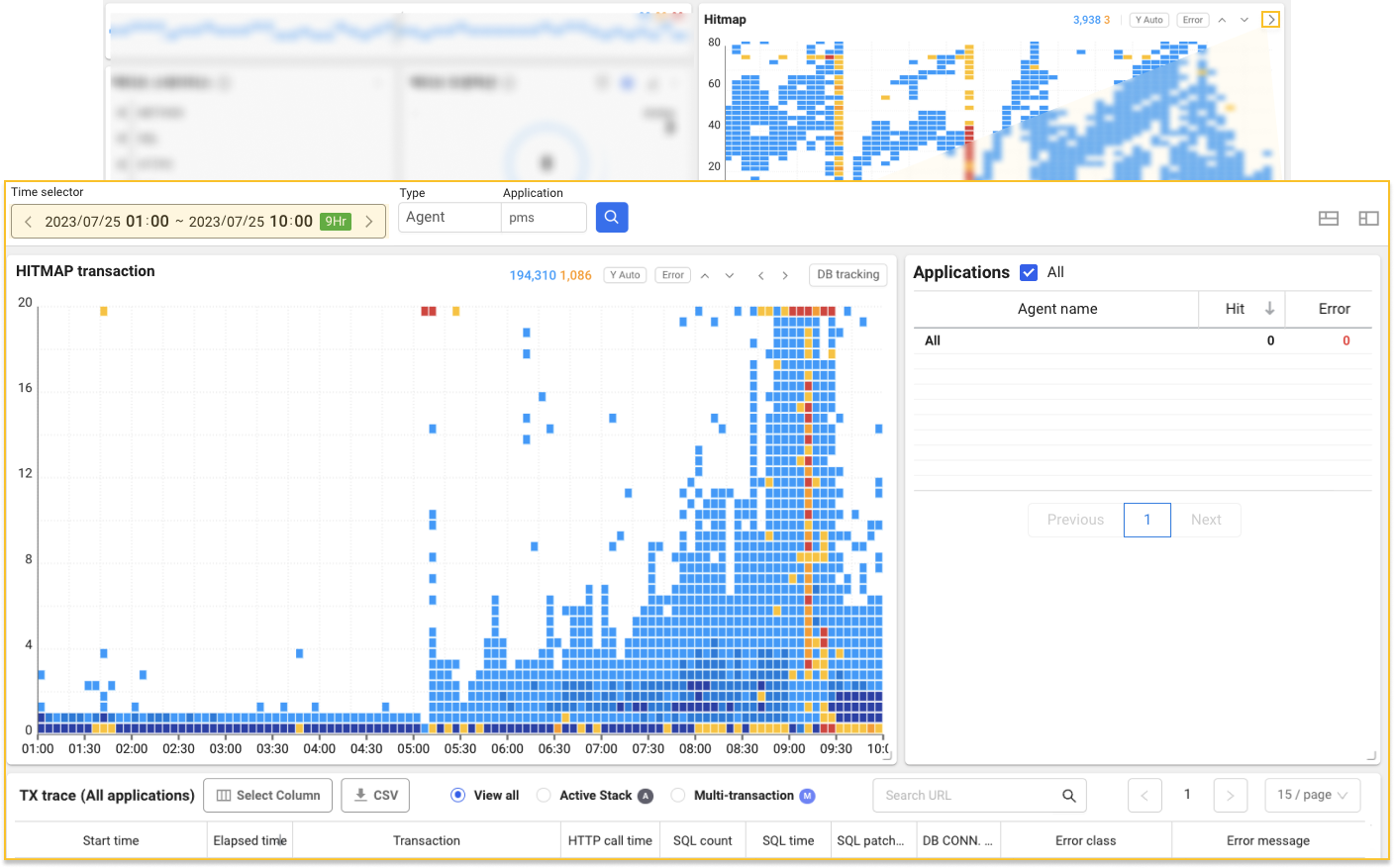
後者の動線で進めてみます。 ダッシュボードヒットマップウィジェットは、過去10分間に終了したトランザクションのレスポンス時間の分布図です。 つまり、時間範囲を特定して直近10分以上の過去の履歴を確認するには、分析メニュー下位のヒットマップメニューに移動する必要があります。 ウィジェット右上の![]() 矢印アイコンを選択して例のように移動できます。
矢印アイコンを選択して例のように移動できます。
ヒットマップトランザクションチャー上段の時間セレクタを通じて希望する時間範囲を指定し、過去の記録を照会することができます。 異常パターンを確定するため、問題区間前後に広く見てみると、レスポンスが遅れているトランザクションが密集した過負荷パターンを確認することができました。
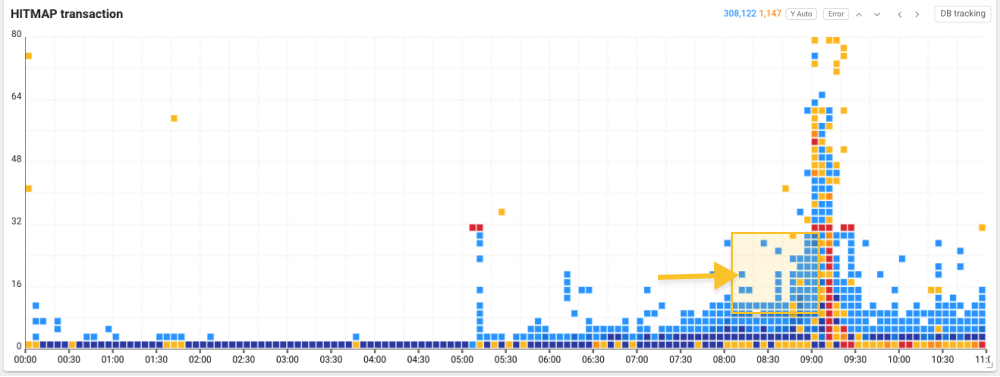
このような突然のレスポンス時間の増加とトランザクション過負荷の原因を特定するためにヒットマップトランザクションチャートから問題領域を区間別にドラッグし、トランザクション トレース一覧(TXトレース一覧)を照会してみます。
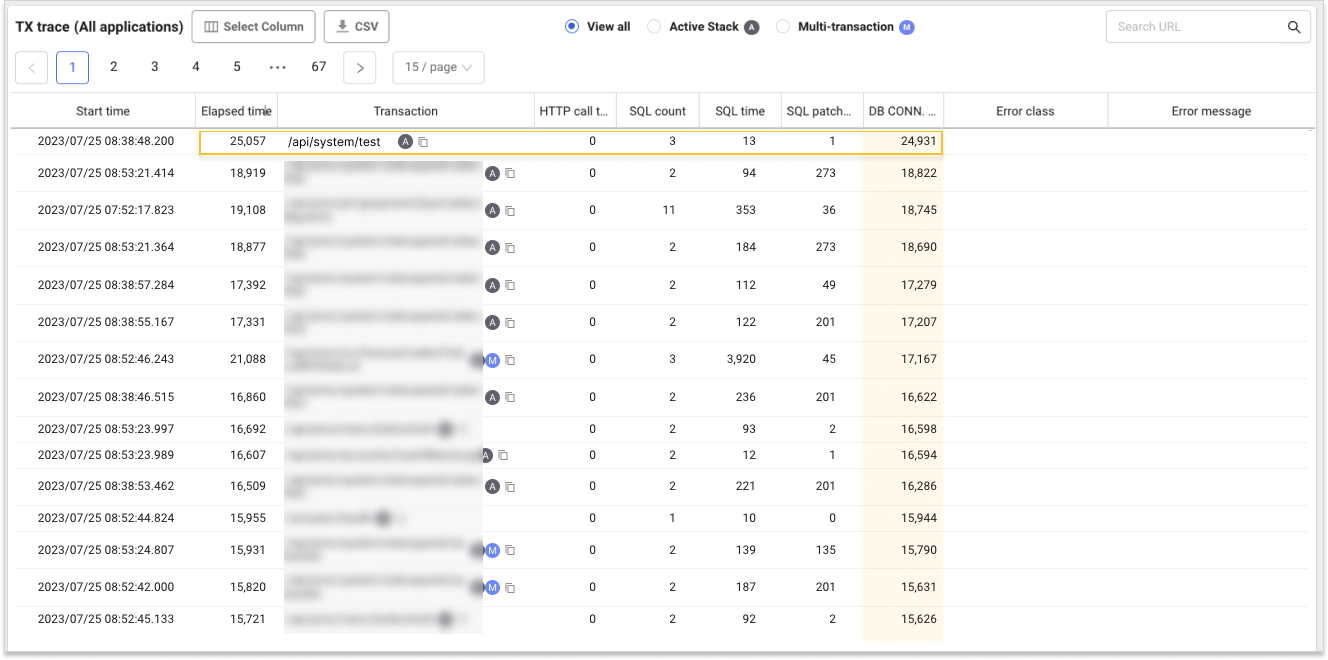
TXトレース一覧を通じて多数のトランザクションで経過時間対比DB接続時間の占める割合が大きいことが確認できます。 例として/api/system/testURLの場合、総経過時間 25,057msのうちDB接続に24,931msがかかりました。 つまり、一次的にDB接続に問題があると推測できます。 次に、当該トランザクションを選択し、トレース情報ウィンドウで詳細情報を見てみましょう。
-
ヒットマップの横軸はトランザクション終了時間、縦軸はレスポンス時間を意味します。 ヒットマップで
 矢印アイコンを選択して、縦軸レスポンス時間の遅延区間を80秒まで照会できます。
矢印アイコンを選択して、縦軸レスポンス時間の遅延区間を80秒まで照会できます。 -
過負荷パターンのほか、ヒットマップパターン分析の詳細については、次の文書を参考にしてください。
トランザクショントレース分析
トレース情報ウィンドウでトランザクションの詳細実行履歴をステップごとに確認できます。 このようなトランザクション トレイシングにより、トランザクションの性能低下またはエラーの原因を追跡できます。 トレース分析ウィンドウを照会する時、最初に確認すべき情報は、ステップ別経過時間です。 所要時間を比較することで、性能低下またはエラーの原因を迅速に特定できるからです。
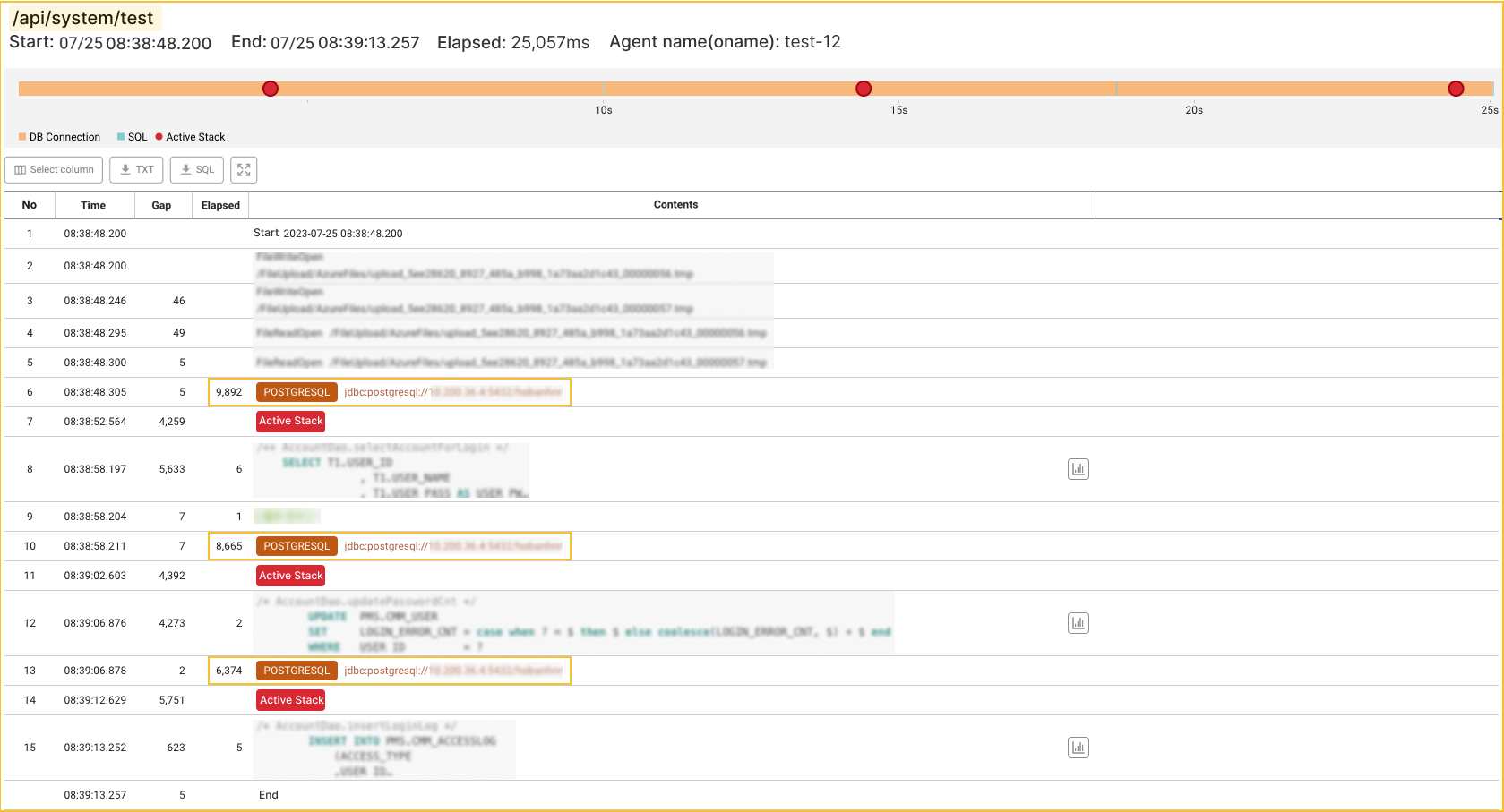
該当URLの詳細トレースを見てみましょう。 /api/system/test実行中、PostgreSQL DBに接続して処理するクエリ実行時間は、1msから6msで、比較的大きな問題はありません。 しかし、当該データベース接続待ち時間はそれに比べて確実に長くかかっており、経過時間を一番多くかけているのがはDB Connectionステップであることが確認できます。
つまり、この場合、先に予想したとおりDB接続遅延によってトランザクション遅延が発生したことを特定できます。 では、このようなDB接続の遅延を引き起こす原因は何でしょうか。
DB Connection Poolの確認
DB連結遅延を起こす原因の一つは、Connection Poolの不足です。 Connection Poolのサイズは、同時に処理可能な接続数を意味します。 データベースは、リクエストによるConnectionを生成し、終了するプロセスに多くの時間を費やします。 Connection Poolは、事前に一定数のConnectionを生成しておいて、他のリクエストがあるときに現在Connection Poolを再使用できるようにします。 これを通じて毎回新しいConnectionを作成する必要がなくなるため、レスポンス時間を短縮できます。 問題は、事前に生成しておいたConnection数が、アプリケーションが必要とするConnection数に比べて足りない場合で、この時にDB接続遅延が発生します。
DB Connection Poolの状況を確認するため分析メニューのメトリクスチャートに移動します。 まず、メトリクスチャート左側のリストでデータベースを選択してDB Pool数とDB Active 数チャートを確認します。
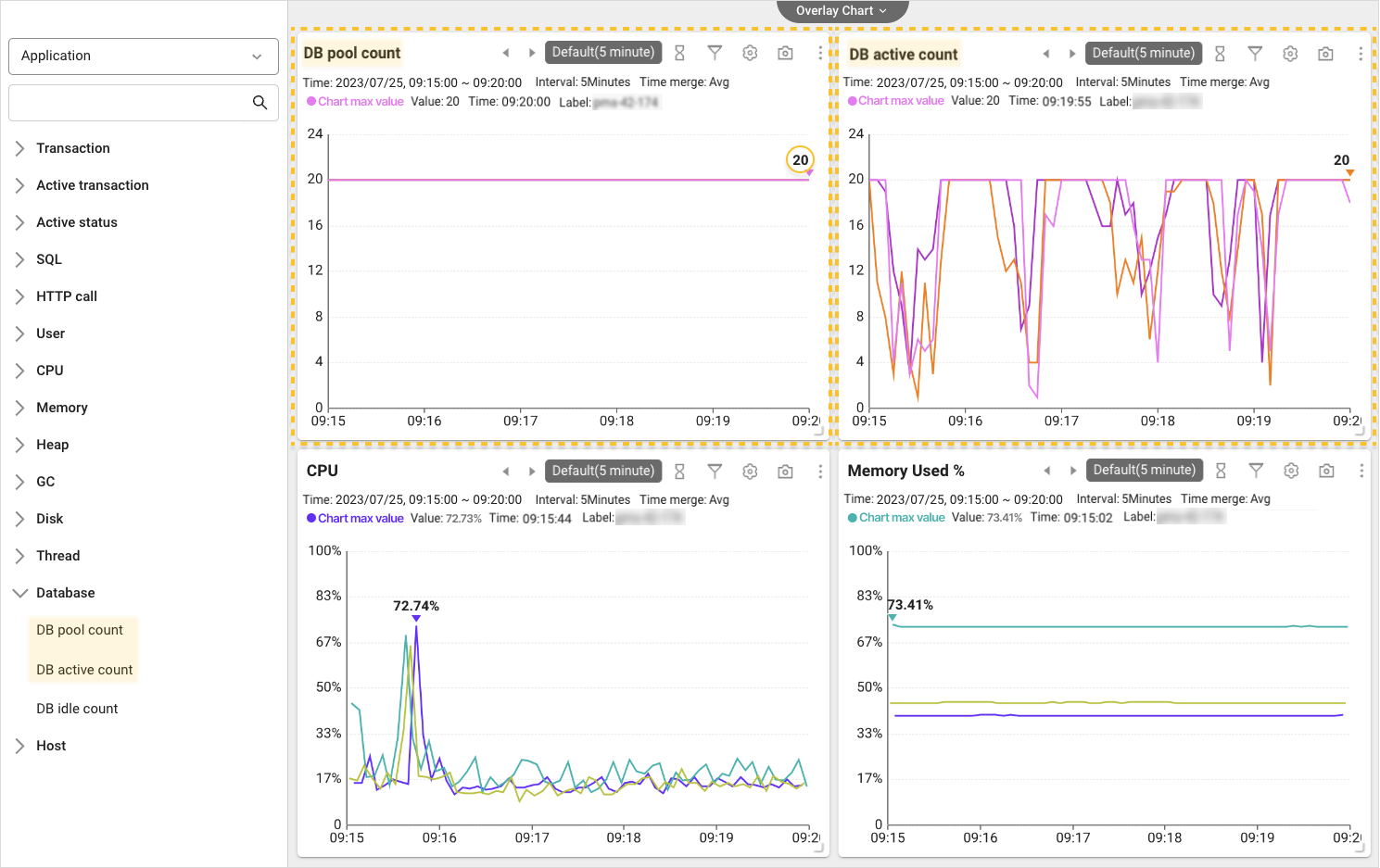
各チャートでも確認できますが、DB Poolの最大接続個数は、20個に設定されています。 DB Active数チャートを見ると、20のプールで継続的な占有が行われていることが確認できます。 事前に設定されたPoolを超えるリクエストが入ってくると、DBに残るPoolができるまで待機し、これにより遅延が発生します。 CPUおよびメモリ使用量など、リソース状況照会時、特異は見つかりませんでした。 つまり、当該プロジェクトの場合、DB Connection Poolの不足がDBC遅延を引き起こした決定的な原因とみられます。
では、このようにDB Connection Poolが足りない場合はどうすればいいでしょうか?。 もちろん、解決方法はユーザー環境によって異なる場合があります。 この文書では、その中でConnection Poolサイズ調整とConnection再利用および最適化による事前措置について簡単に案内します。
Connection Poolサイズ調整
まず、Poolの最大接続数を調整する方法を活用できます。 Poolを次第に増やしてDB Active数がPoolの最大値内で維持されることを確認し、適切なPool数を設定することです。 しかし、Poolの数を過度に大きく指定した場合、リソース消費量の過度な増加により、むしろアプリケーション性能に悪影響を与える可能性があります。 十分なメモリと処理能力を備えていることを確認した後、各自の運営環境に合わせて調整する必要があります。
Connection再利用および最適化
2番目にConnection再利用および最適化による方法を活用できます。 例えば、アプリケーションが使用したConnectionを返さないConnection Leakが発生した場合なら、いくらConnection Pool数を増やしたとしても、その現象を解決することはできません。 この場合、DB Active数は、右上向グラフを描くことになります。 Connection Leakを防ぐためには、使用したConnectionを必ず返却するように管理する必要があります。 Connection使用後、明示的に返すように設定したり再利用する方式を適用してみることができます。