Top 오브젝트
홈 화면 > 프로젝트 선택 > 분석 > Top 오브젝트
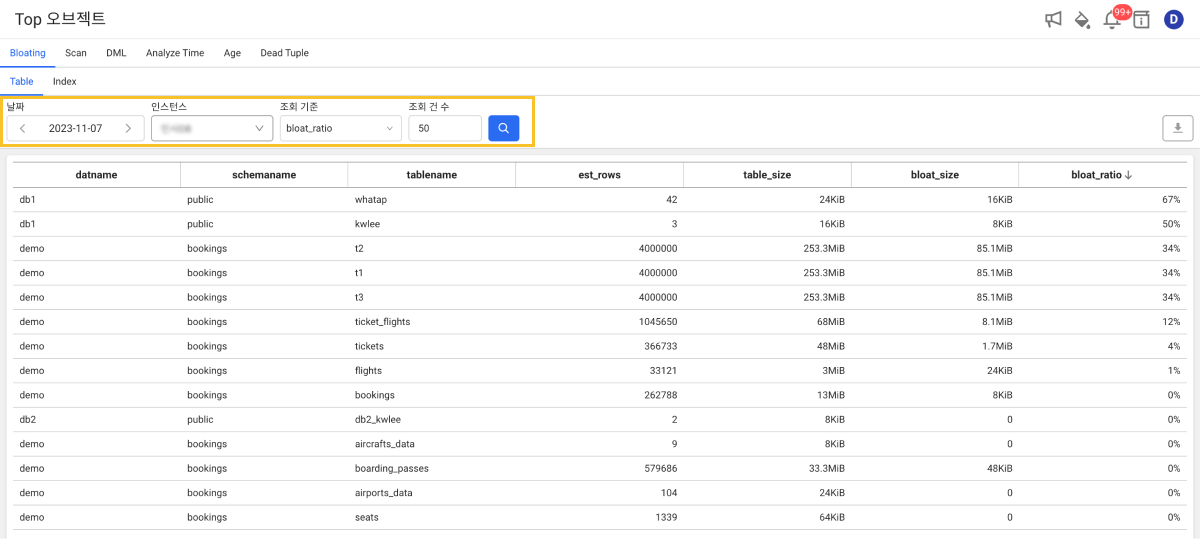
개별 인스턴스의 오브젝트(테이블, 인덱스)별 Bloating 사이즈, Scan 수, DML 수행 수, Dead tuple이 많은 오브젝트를 제공하며 사용이 많은 오브젝트를 파악하고 Vacuum이나 Analyze를 적절한 시기에 수행할 수 있는 정보를 제공합니다.
-
화면에서 조회하길 원하는 날짜와 인스턴스, 조회 기준, 조회 건 수를 설정한 다음
 버튼을 선택하세요. 선택한 조건에 따른 결과가 테이블에 표시됩니다.
버튼을 선택하세요. 선택한 조건에 따른 결과가 테이블에 표시됩니다. -
조회 목록에서 tablename 또는 indexname 컬럼 항목을 선택하면 column, index 구성을 확인할 수 있는 Object detail 창이 나타납니다.
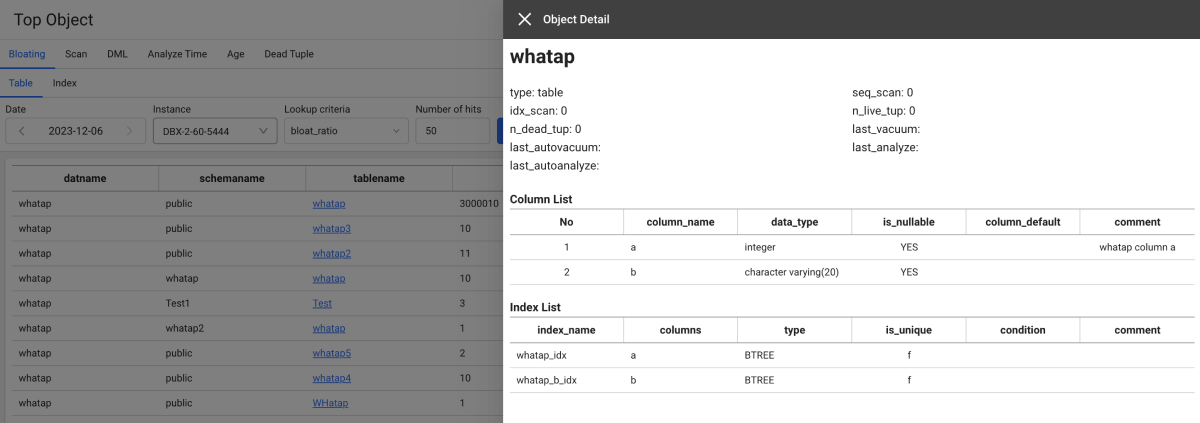 노트
노트Object detail 기능은 DBX 에이전트 1.6.15 버전 이상에서 지원합니다. 데이터베이스 권한과 관련한 설정은 다음 문서를 참조하세요.
-
Top 오브젝트에 대한 정보는 하루에 한번 수집합니다. 관련한 에이전트 설정에 대한 자세한 내용은 다음 문서를 참조하세요.
-
데이터 조회를 위해서는 DB 모니터링 계정에 다음 권한이 필요합니다.
grant select on all tables in schema {schema_name} to whatap; -
이 기능은 DBX 에이전트 1.6.13 버전 이상에서 지원합니다.
Bloating
Bloating은 실제 사용되지 않는 tuple이 증가하여 오브젝트 크기가 커지는 현상입니다.
에이전트 설정(whatap.conf)의 table[index]_bloat_ratio[bytes]에 설정된 수집 기준보다 큰 값을 가지는 테이블과 인덱스를 목록에 표시합니다. 해당하는 오브젝트가 없으면 데이터가 조회되지 않을 수 있습니다.
튜닝 팁
Bloat_ratio가 높은 테이블은 Vacuum 수행을 검토하세요. 자세한 내용은 다음 문서를 참조하세요.
다음은 Bloating을 조회하면 표시되는 컬럼 항목입니다.
| 구분 | 컬럼 이름 | 설명 |
|---|---|---|
| Table | datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 | |
tablename | 테이블 이름 | |
est_rows | Dead tuple + Live tuple 건수로 예측한 값 | |
table_size | 테이블 사이즈 | |
bloat_size | Dead tuple로 인해 부풀려진 예상 테이블 사이즈 | |
bloat_ratio | 부풀려진 사이즈 비율 입니다. | |
| Index | datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 | |
tablename | 테이블 이름 | |
indexname | 인덱스 이름 | |
table_size | 테이블 사이즈 | |
index_size | 인덱스 사이즈 | |
bloat_size | Dead tuple로 인해 부풀려진 예상 인덱스 사이즈 | |
bloat_ratio | 부풀려진 사이즈 비율 | |
index_scans | 인덱스를 사용한 경우 index scan 회수 |
Scan
Seq_scan은 인덱스를 사용하지 않은 Full Sacn을 의미하며, idx_scan은 인덱스를 사용한 수를 의미합니다.
튜닝팁
Seq_scan이 높은 테이블은 인덱스 생성을, idx_scan이 낮은 인덱스는 삭제를 검토하세요. 자세한 내용은 다음 문서를 참조하세요.
다음은 Scan을 조회하면 표시되는 컬럼 항목입니다.
| 구분 | 컬럼 이름 | 설명 |
|---|---|---|
| Table | datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 | |
tablename | 테이블 이름 | |
seq_scan | 해당 테이블을 순차 스캔(Full scan)한 수 | |
seq_tup_read | 순차 스캔에서 가져온 라이브 행 수 | |
idx_scan | 해당 테이블의 인덱스 스캔 수 | |
idx_tup_fetch | 인덱스 스캔으로 읽은 라이브 행 수 | |
| Index | datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 | |
tablename | 테이블 이름 | |
indexname | 인덱스 이름 | |
idx_scan | 인덱스 스캔 실행 수 | |
idx_tup_fetch | 해당 인덱스를 사용해 인덱스 스캔에서 추출된 유효한 테이블 행 수 | |
idx_tup_read | 인덱스 스캔에 반환된 인덱스 항목 개수 |
DML
dml_count 값이 높은 테이블은 사용이 많은 주요 테이블입니다.
튜닝 팁
사용하는 시스템의 주요 테이블을 파악하여 테이블 변경이나 아키텍처 설계 시 참고하세요.
다음은 DML을 조회하면 표시되는 컬럼 항목입니다.
| 컬럼 이름 | 설명 |
|---|---|
datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 |
tablename | 테이블 이름 |
dml_count | n_tup_ins + n_tup_upd + n_tup_del |
n_tup_ins | 삽입(Insert)된 행 수 |
n_tup_upd | 업데이트(Update)된 행 수 |
n_tup_del | 삭제(Delete)된 행 수 |
n_tup_hot_upd | HOT 업데이트 된 행 수 (예를 들어, 따로 인덱스 업데이트 필요가 없는) |
Analyze Time
Analyze와 Vacuum 수행이 오래된 오브젝트 목록입니다.
튜닝 팁
오래된 테이블은 통계정보가 부정확할 수 있습니다. 수행을 검토하세요. 자세한 내용은 다음 문서를 참조하세요.
다음은 Analyze Time을 조회하면 표시되는 컬럼 항목입니다.
| 컬럼 이름 | 설명 |
|---|---|
datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 |
tablename | 테이블 이름 |
last_analyze | 테이블을 수동 분석한 마지막 시간 |
last_autoanalyze | autovacuum 데몬으로 테이블을 분석한 마지막 시간 |
last_autovacuum | autovacuum 데몬으로 테이블을 청소(vacuum)한 마지막 시간 |
analyze_count | 수동으로 분석한 횟수 |
last_vacuum | 테이블이 수동으로 청소(vacuum)한 마지막 시간(VACUUM FULL은 해당되지 않음) |
autoanalyze_count | autovacuum 데몬으로 분석한 횟수 |
autovacuum_count | autovacuum 데몬으로 청소(vacuum)한 횟수 |
vacuum_count | 수동으로 청소(vacuum)한 횟수(VACUUM FULL은 제외) |
n_mod_since_analyze | 마지막 분석(analyze) 이후 변경된 행수 수(추정치) |
Age
PostgreSQL에서는 XID(transaction id)를 순환적으로 사용하여 어느 순간 XID가 랩어라운드(Wraparound)될 수 있습니다. 이를 방지하기 위해 xid_age(Current XID - 생성 시점의 XID)가 계속 증가하지 않도록 관리되어야 합니다. autovacuum_freeze_max_age를 초과하면 Anti-Wraparound Vacuum을 자동으로 수행하게 되어 autovacuum_freeze_max_age 이하로 xid_age를 관리합니다.
이 목록은 아래 기준에 해당하는 vacuum 대상이 있는지 조회합니다. 대상이 없으면 데이터가 조회되지 않을 수 있습니다.
-
dead tuple 수가 vacuum threshold(
autovacuum_threshold+autovacuum_scale_factor*number-of-tuples) 보다 많은 테이블 -
age(
relfrozenxid)가autovacuum_freeze_max_age보다 큰 테이블
튜닝 팁
xid_age가 계속 증가하고 있다면 현재 설정된 Auto Vaccum 조건으로 XID 정리 작업이 진행되지 않는 것일 수 있습니다. auto vacuum 파라미터를 조정하거나 수동으로 Vacuum 수행을 검토하세요.
자세한 내용은 다음 문서를 참조하세요.
다음은 Age을 조회하면 표시되는 컬럼 항목입니다.
| 컬럼 이름 | 설명 |
|---|---|
datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 |
tablename | 테이블 이름 |
xid_age | 테이블의 max age, 가장 오래된 레코드의 xid(트랜잭션 ID) |
per_to_wraparound | xid(트랜잭션 ID) 래핑까지의 남은 여유를 백분율로 표시한 지표계산식: per_to_wraparound(%) = xid_age / Autovacuum_freeze_max_age * 100 |
table_size | 테이블 사이즈 |
autovacuum_vacuum_tuples | 이 값보다 Dead tuple 갯수가 많아지면 autovacuum을 수행합니다. |
dead_tuples | Dead tuple 수 |
autovacuum_freeze_max_age | 기본값 2억으로 설정됨 |
Dead Tuple
Dead tuple은 Delete나 Update로 이미 지워진 자료입니다. free space로 바꾸기 위해 Vacuum 수행을 검토합니다.
튜닝 팁
Dead tuple을 줄이기 위해서는 Vacuum 수행을 검토하세요. 자세한 내용은 다음 문서를 참조하세요.
다음은 Dead Tuple을 조회하면 표시되는 컬럼 항목입니다.
| 컬럼 이름 | 설명 |
|---|---|
datname | 데이터베이스 이름 |
schemaname | 스케마(schema) 이름 |
tablename | 테이블 이름 |
dead_tuple | Delete나 Update 등에 의해 사용하지 않는 튜플(Tuple)의 개수 |
dead_tuple_ratio | 사용하지 않는 튜플(Tuple)의 비율 |
live_tuple | 사용하는 튜플(Tuple)의 개수 |
live_tuple_ratio | 사용하는 튜플(Tuple)의 비율 |
total_relation_size | 릴레이션의 전체 크기, 인덱스와 TOAST 데이터 포함 |
total_tuple | 전체 튜플(Tuple)의 개수 |
에이전트 설정
다음은 Top 오브젝트에 대한 정보를 조회하기 위한 에이전트 설정입니다. whatap.conf 파일에 필요한 옵션을 설정하세요.
-
pg_object Boolean
기본값
falseTop 오브젝트의 정보 수집 여부를 설정합니다. 정보를 수집하려면
true로 변경하세요. -
pg_object_hour Int
기본값
5Top 오브젝트의 정보를 수집 시각을 설정합니다. 기본값은
5이며 새벽 5시에 수집을 시작합니다. -
table_bloat_ratio Percentage
기본값
50테이블 bloating ratio 값이 설정값 이상인 경우 정보를 수집합니다. 기본값은 50%입니다.
-
table_bloat_bytes Byte
기본값
10485760테이블 bloating bytes 값이 설정값 이상인 경우 정보를 수집합니다. 기본값은 10MB입니다.
-
index_bloat_ratio Percentage
기본값
50인덱스 bloating ratio 값이 설정값 이상인 경우 정보를 수집합니다. 기본값은 50%입니다.
-
index_bloat_bytes Byte
기본값
10485760인덱스 bloating bytes 값이 설정값 이상인 경우 정보를 수집합니다. 기본값은 10MB입니다.
-
autovacuum_list_limit Int
기본값
50가장 오래된 age(
relfrozenxid) 순으로 설정값만큼 테이블 정보를 수집합니다. 기본값은 50개입니다.