네트워크 성능 모니터링
네트워크 성능 모니터링(Network Performance Monitoring, 이하 NPM)은 네트워크 간의 혼잡 및 장애를 파악하고 사용자의 네트워크 성능 개선에 활용하기 위하여 프로세스의 네트워크 통신 정보를 수집하여 가시화하는 솔루션입니다.
네트워크 성능 모니터링의 필요성
네트워크 환경 변화
네트워크 모니터링은 기존의 장비 중심의 모니터링에서 프로세스 중심의 모니터링으로 변화해야 합니다. 과거의 네트워크 모니터링은 서버 및 네트워크 장비에 종속적인 정보를 SNMP 프로토콜을 통해 획득해서 가시화시켜 주는 형태로 운영됐습니다. 최근 네트워크 시장은 클라우드와 가상화라는 큰 틀에서 성장하고 있으며 이로 인해 기존의 모니터링 방식으로는 장애 상황 및 요소를 판단하기 어려워지고 있습니다.
-
클라우드
기존의 서버 및 네트워크 장비를 통해 서비스를 운영하던 온-프레미스(On-premise) 환경에서 클라우드 서비스 제공 업체(CSP)가 제공하는 가상 환경에서 서비스를 운영하는 환경으로 변화하고 있습니다. 물리적 실체가 없는 클라우드 환경에서 중요한 모니터링 대상은 실제 작업을 수행하는 프로세스 입니다.
-
가상화
컨테이너 기반의 가상화 환경에서는 여러 컨테이너가 단일 장비에서 실행됩니다. 각 컨테이너는 독립된 네트워크 스택을 가지며 하나의 장비에서도 여러 컨테이너 간의 통신이 존재합니다. 기존의 장비 기반의 네트워크 모니터링을 통해서는 문제가 발생한 컨테이너 및 프로세스까지 구분하는 것은 어렵습니다.
Network Function Virtualization(NFV)을 통해 기존의 별도의 H/W로 구현된 네트워크 기능들을 소프트웨어로 가상화시키는 노력도 계속해서 진행되고 있습니다.
기존의 네트워크 성능 모니터링 방식으로는 클라우드와 가상화로 인해 추적하지 못하는 그레이존이 생겨나게 됐습니다. 와탭의 NPM은 프로세스를 대상으로 네트워크 동작을 추적하기 때문에 클라우드와 가상화에 대한 환경 변화를 대응할 수 있습니다.
네트워크 복잡성 증가
Micro Service Architecture(MSA) 기반의 서비스들이 많아지고 있고 특유의 유연성과 확장성으로 인해 네트워크 관계가 복잡해지고 있습니다. 고가용성(High Availability, HA) 구성이나 Scale Out 등 서비스 안정화를 위해 수행하는 작업들도 네트워크 복잡성에 영향을 주고 있습니다. 관계가 복잡해짐에 따라 부하 발생 여부를 인지하고 구간을 판별해 내는 과정이 점점 더 어려워지고 있습니다.
와탭의 NPM은 각 프로세스가 수행하는 네트워크 동작들을 추적하여 복잡한 구성 요소와 상태 정보를 토폴로지를 통해 직관적으로 이해할 수 있도록 시각화했습니다.
기대 효과
프로세스 단위로 수집되는 지표들을 통해 다음의 효과를 기대할 수 있습니다.
-
프로세스 단위의 네트워크 지표 모니터링
-
서비스 종속성 파악 및 개선
-
네트워크 비용 최적화
-
네트워크 장애에 대한 MTTD, MTTR 감소
-
MTTD(Mean Time To Detect): 장애를 인지하는데 걸리는 시간
-
MTTR(Mean Time To Repair): 장애 발생 인지 후 장애를 복구하는데 걸리는 시간
-
주요 특징
복잡한 네트워크를 그룹화하여 구간별 성능 지표를 빠르게 모니터링합니다. 네트워크 장애를 빠르게 대처할 수 있는 토폴로지 대시보드를 통해 그룹화, 단순화한 네트워크 정보를 통해 네트워크 장애 여부를 빠르게 파악할 수 있습니다.
-
안정적이고 세부적인 데이터 수집
와탭 NPM에서는 eBPF 기술을 활용해 데이터를 수집합니다. eBPF 기술은 커널에서 발생하는 다양한 이벤트들을 수집하여 샌드박스 환경에서 추가적인 동작을 실행시켜 주는 기술입니다. 커널 이벤트를 수집하기 때문에 프로세스 레벨의 상세한 정보를 획득하고 샌드박스 기반인 만큼 안정적인 운영이 가능합니다.
-
태그 옵션을 통한 가시성 확보
네트워크 모니터링 제품은 다양하고 복잡한 네트워크 데이터를 쉽게 이해할 수 있도록 제공 가능해야 합니다. 와탭 NPM은 사용자의 목적과 의도에 따라 네트워크 요소들을 표현할 수 있도록 태그 옵션을 지원합니다. 고객 서비스 특성에 맞게 다양한 커스텀이 가능합니다.
-
Raw Data를 통한 트러블 슈팅
서버에 접속하지 않아도, 장애 상황이 해소된 뒤에도 특정 시점에 네트워크 상태를 지표 기준으로 확인 가능하며 관련된 서버 및 프로세스 등 문제 파악을 지원합니다.
노트Raw Data를 활용하는 메뉴에 대한 자세한 내용은 다음 문서를 참조하세요.
-
Flex 보드를 통한 다양한 기준의 커스텀 차트
수집되는 정보들을 통해 다양한 기준으로 커스텀 차트를 만들 수 있습니다.
주요 지표 안내
5가지의 네트워크 지표를 통해 네트워크 성능을 모니터링합니다.
-
품질 지표
Latency와 Jitter 지표를 제공하며 성능 이슈 및 장애 여부를 판단하는 기준으로 이용합니다. TCP 기반의 네트워크 통신을 활용하는 케이스에서 수집이 가능합니다.
-
Latency: 네트워크 응답 시간을 의미하는 지표입니다. 응답 시간이 높은 구간은 최종 사용자에게 직접적으로 좋지 않은 경험을 제공할 수 있습니다.
-
Jitter: 네트워크 응답 시간의 변동성을 의미하는 지표입니다. Jitter 값이 높다는 의미는 해당 구간의 네트워크 혼잡, 패킷 이동 경로의 변화가 자주 발생한다는 의미로 해석할 수 있습니다. 특정 네트워크 구간의 장애를 의심할 수 있으며 또한 패킷 도착 순서가 꼬이면서 패킷 재전송 및 누수를 유발하여 전체적인 서비스 품질의 저하로 귀결됩니다.
-
-
네트워크 사용량 지표
bps, pps, session count, 세가지 기준으로 네트워크 사용량에 대한 정보를 제공하며 의도하지 않은 외부 트래픽의 유입(DDoS 등)이나 트래픽의 패턴 등을 통해 클라우드 환경을 최적화하는데 활용할 수 있습니다.
-
bps: bits per second(bps)는 초당 전송 bit 수를 나타내는 지표입니다.
-
pps: packets per second(pps)는 초당 전송 패킷 수를 나타내는 지표입니다.
-
session count: 유니크한 세션 개수를 나타내는 지표입니다.
-
지표 활용 안내
-
네트워크 지표들은 서버의 CPU 사용량과 비슷하게 사용자의 목표 임계치가 있는 것이 좋습니다.
-
서비스 신뢰성을 위해 SLI(서비스 레벨 지표), SLO(서비스 레벨 목표)를 정의하고 이를 바탕으로 일정 수준의 서비스를 꾸준히 제공할 수 있어야 합니다.
-
만약 목표 값이 불분명하다면 와탭에서 제공하는 초기 기준으로 데이터를 수집하고 이후에 목표를 정하고 서비스를 개선을 시도하세요.
-
-
현재 와탭에서는 기본 임계치를 다음과 같이 적용합니다. 사용자 환경 및 SLO 목표 값에 맞춰 변경 가능합니다.
-
Jitter: 30ms
-
Latency: 200ms
-
bps: 128Mib/s
-
pps: 50k
-
session count: 100
-
-
토폴로지에 임계치를 적용해 임계치를 넘은 구간을 빠르게 파악하고 개선 여부 판단을 지원합니다.
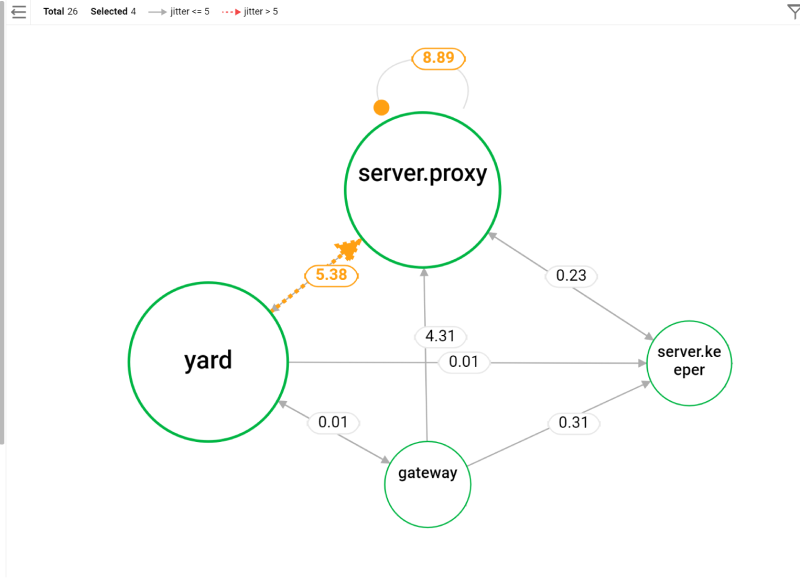
-
각 지표들이 임계치를 넘은 시점에 알림을 보내고 해당 이벤트 정보를 확인할 수 있습니다.
-
네트워크 지표들은 일반적인 상황에서 평평한 수평 형태의 차트를 기대합니다. 평균 값에서 급격히 변화하는 지표들을 통해 장애를 여부를 판단하고 구간을 식별할 수 있습니다.