메트릭스 가공
MXQL 문법을 이용해 메트릭스를 가공하는 명령어에 대해서 알아봅니다. 메트릭스 가공 단계는 조회된 데이터들이 각 단계를 순차적으로 수행하는 구조입니다. 따라서 이 단계에 포함되는 명령어들의 입력 순서가 중요합니다.
| 명령어 | 기능 |
|---|---|
| ROWNUM | 줄번호 필드를 추가합니다. |
| SELECT | 필드를 선택합니다. 선택되지 않은 필드은 조회되지 않습니다. |
| CREATE | 필드를 추가합니다. |
| DELETE | 필드를 삭제합니다. |
| RENAME | 필드의 이름을 변경합니다. |
| GROUP | 데이터를 그룹화합니다. |
| ORDER | 데이터를 정렬합니다. |
| JOIN | 다른 MQL에서 조회한 데이터를 본 데이터에 컬럼단위로 추가할때 사용합니다. |
| UPDATE | 데이터를 가공, 정제합니다. |
| LIMIT | 추출되는 데이터의 수를 제한합니다. |
| SKIP | 해당 위치에서 조회되는 일부 데이터를 무시합니다. |
| FILTER-KEYS | 특정 데이터를 가지고 있는 데이터만 추출합니다. |
| FIRST-ONLY | 데이터 중에서 처음 데이터만을 통과 시키고 나머지는 버립니다. |
| TIME-FILTER | 특정시간의 데이터를 SKIP할때 사용합니다. |
| INJECT | 해당 위치에 MXQL 쿼리를 추가합니다. |
| ADJUST | 숫자 필드의 값을 변경하기 위해 사용합니다. |
| FILTER | 특정 조건을 가지고 있는 데이터만 다음 단계로 전달합니다. |
ROWNUM
줄번호 필드를 추가합니다.
CATEGORY agent_list
FLEXLOAD
ROWNUM
SELECT
필드를 선택합니다. 선택하지 않은 필드는 다음 단계로 전달하지 않습니다.
| 옵션 이름 | 옵션 기능 |
|---|---|
| default | like, notlike와 상관없이 조회하고 싶은 필드를 설정합니다. |
| like | 설정한 값을 부분 문자열로 가지는 필드만 조회합니다. |
| notlike | 설정한 값을 부분 문자열로 가지지 않는 필드만 조회합니다. |
-
모든 필드를 선택하는 경우 1 (
SELECT명령어, 오퍼랜드를 모두 입력하지 않은 경우)CATEGORY app_counter
TAGLOAD -
모든 필드를 선택하는 경우 2 (
SELECT명령어의 오퍼랜드를 입력하지 않은 경우)CATEGORY app_counter
TAGLOAD
SELECT -
조회하고 싶은 필드 이름을 직접 설정하는 경우, 문자열배열 오퍼랜드를 사용합니다.
CATEGORY app_counter
TAGLOAD
SELECT [time, pcode] -
default로 설정할 필드의 값이 하나인 경우와like옵션을 사용하는 경우CATEGORY app_counter
TAGLOAD
SELECT {default:time, like:_m} -
default로 설정할 필드의 값이 여러 개인 경우와like옵션을 사용하는 경우,default로 설정할 필드의 값이 여러 개인 경우와like옵션을 사용하는 경우CATEGORY app_counter
TAGLOAD
SELECT {default:[time,name], like:_m} -
like와notlike를 모두 사용하고 싶은 경우SELECT명령어를 두 번에 나누어서 입력해야 합니다.CATEGORY app_counter
TAGLOAD
SELECT {default:[time,name], like:name}
SELECT {notlike:pname}
- 만약 전체 필드를 선택할때는 오퍼랜드를 입력하지 않습니다.
like와notlike는 한 번에 설정할 수 없습니다. 여러 번의SELECT에서 나누어서 설정해야 합니다.
SELECT 명령어는 출력되는 필드 순서를 변경할 때도 사용합니다.
CREATE
필드를 추가합니다.
| 옵션 이름 | 옵션 기능 |
|---|---|
| value | 특정 값을 가지는 필드를 생성합니다. |
| from | 설정한 필드의 값을 가지는 필드를 생성합니다. |
| expr | 입력한 수식의 결과를 값으로 가지는 필드를 생성합니다. 수식에는 필드의 이름이 사용될 수 있습니다. |
| oname | oid 컬럼의 이름을 설정하여 oid 값에 대응되는 oname의 값을 가지는 컬럼을 생성합니다. |
| okind | okind 컬럼의 이름을 설정하여 okind 값에 대응되는 okind name의 값을 가지는 컬럼을 생성합니다. |
| onode | onode 컬럼의 이름을 설정하여 onode 값에 대응되는 onode name의 값을 가지는 컬럼을 생성합니다. |
-
value속성을 설정하는 경우CATEGORY app_counter
TAGLOAD
CREATE {key:active$, value:'#'} -
from속성을 설정하는 경우CATEGORY app_counter
TAGLOAD
CREATE {key:_id_, from:okind } -
expr속성을 설정하는 경우CATEGORY app_counter
TAGLOAD
CREATE { key:apdex, expr:" (apdex_satisfied(apdex_tolerated*0.5))/apdex_total " } -
okind속성을 설정하는 경우CATEGORY agent_list
FLEXLOAD
CREATE { key : my_okind_name, okind : okind}
SELECT [ time, okind, okindName, my_okind_name]
DELETE
필드를 삭제합니다.
CATEGORY app_counter
TAGLOAD
DELETE [pcode]
반드시 문자열 배열로 입력해야합니다. DELETE pcode는 동작하지 않습니다. (2021-06-23 기준)
RENAME
필드의 이름을 변경합니다.
-
pcode필드의 이름my_pcode로 변경합니다.CATEGORY app_counter
TAGLOAD
RENAME { src : pcode, dst : my_pcode }
time은 ORDER에서 최우선으로 사용하는 정렬 기준으로 time의 이름을 임의로 변경하면 ORDER가 동작하지 않을 수 있습니다.
GROUP
데이터를 그룹화합니다.
| 옵션 이름 | 옵션 기능 |
|---|---|
| timeunit | 그룹을 나눌 시간 기준을 설정합니다. |
| pk or primaryKey | 그룹의 primaryKey를 설정합니다. |
| last | 설정한 컬럼(column)의 데이터 중 마지막 값만 저장하고 싶을 때 설정합니다. oname과 같이 반복해서 같은 값이 사용될 때 사용합니다. 내부적으로 설정한 값을 key로 가지는 값에 계속 덮어써집니다. |
| listup | 설정한 컬럼(column)의 데이터를 모두 메모리에 저장하고 싶을 때 설정합니다. 내부적으로는 설정한 값을 key로 가지는 List에 계속 값이 추가됩니다. |
| user | 실시간 사용자를 계산하기 위한 옵션입니다. Blob 타입의 데이터를 저장한 컬럼(column)만 설정할 수 있습니다.(app_user 카테고리의 logbits 등) |
| merge | 설정한 컬럼(column)의 데이터를 MetricValue(복합값)으로 저장하고 싶을 때 설정합니다. 내부적으로는 설정한 값을 key로 가지는 MetricValue값에 추가됩니다. |
| rows | 하나의 그룹에 최대로 저장될 수 있는 데이터의 수를 설정합니다. 기본값은 10000입니다. |
-
설정한 필드에 대해
merge로 설정하여 MetricValue로 설정한 뒤 sum 연산을 수행합니다.CATEGORY app_counter
TAGLOAD
SELECT [ time, okindName, okind, apdex_satisfied, apdex_tolerated, apdex_total]
GROUP { timeunit:5000, pk:okind, last:okindName, merge:[apdex_satisfied, apdex_tolerated, apdex_total] }
UPDATE { key:[apdex_satisfied, apdex_tolerated, apdex_total], value:sum }
원칙적으로 merge 필드는 별도로 설정해야 합니다. 하지만 last, merge, listup 세 가지 속성을 모두 명시하지 않은 경우에는 모든 number 필드는 merge 필드로, number 필드가 아닌 필드는 last 필드로 자동 선택 됩니다.
만약 레코드에 time 필드가 없으면 전체를 그룹핑합니다.
GROUP명령어가 수행되기 전에SELECT명령어로time필드를 설정하지 않은 경우RENAME명령어로time필드의 이름을 변경한 경우DELETE명령어로time필드를 삭제한 경우
UPDATE
필드의 데이터를 수정합니다. MetricValue 상태인 필드에 대해서 연산을 선택할 수 있습니다.
| 옵션 | 기능 |
|---|---|
| sum | MetricValue에 포함된 값을 더합니다. |
| min | MetricValue에 포함된 값 중 최소값을 구합니다. |
| max | MetricValue에 포함된 값 중 최대값을 구합니다. |
| last | MetricValue에 포함된 값 중 마지막에 추가된 값을 구합니다. |
| avg | MetricValue에 포함된 값의 평균을 구합니다. |
| cnt | MetricValue에 포함된 값의 갯수를 구합니다. |
| datetime | 시간 데이터의 형식을 변경합니다. |
| timezone | 시간 데이터의 기준을 설정합니다. |
| notnull | 설정한 컬럼의 값이 null인 경우 적용할 default 값을 설정합니다. |
| pct | GROUP 명령 수행 시 percentile을 위해 필드의 모든 값을 listup 했을 경우 percentile 값을 필드값으로 변경할 수있습니다. |
| decimal | 필드의 숫자 데이터를 포멧팅 할 수 있습니다. |
다음의 옵션을 설정해 데이터의 값을 수정할 수 있습니다.
-
value옵션을 설정하는 경우CATEGORY app_counter
TAGLOAD
SELECT [time, pcode,pname, tps]
GROUP {timeunit:5000, pk:pcode, last: pname, merge:tps}
UPDATE {key:tps, value:sum} -
datetime,timezone옵션을 설정하는 경우CREATE {key:localtime, from:time}의 경우time필드의 값long타입의 값으로 복사합니다.CATEGORY app_user
TAGLOAD
SELECT [time, pcode, pname, logbits]
CREATE {key:localtime, from:time}
UPDATE {key:localtime, datetime:'yyyyMMdd HH:mm:ss', timezone: GMT9} -
notnull옵션을 설정하는 경우UPDATE {key:tps, notnull:0} -
pct를 설정하는 경우CATEGORY app_counter
TAGLOAD
SELECT [ time, pcode, tx_count ]
GROUP { key : pcode, listup : tx_count}
UPDATE { key : tx_count, pct : 90} -
decimal옵션을 설정하는 경우CATEGORY app_counter
TAGLOAD
SELECT [ time, oname, apdex_satisfied, apdex_tolerated, apdex_total]
GROUP { timeunit:5m, pk:oname}
UPDATE { key:[apdex_satisfied, apdex_tolerated, apdex_total], value:sum }
CREATE { key:apdex, expr:" (apdex_satisfied(apdex_tolerated/2.0))/apdex_total " }
UPDATE { key:time, datetime:'yyyyMMdd HH:mm:ss', timezone:'GMT9'}
UPDATE { key:apdex, decimal:'0.000'}
ROWNUM
{datetime:'yyyyMMdd HH:mm:ss'}의 경우, 문자 쌍점(:)을 포함하고 있어, 반드시 작은 따옴표('') 또는 큰 따옴표("")로 감싸주어야 합니다.pct: 90은 90%번째의 값을 선택한다는 의미입니다. 단, 해당 필드는GROUP명령을 수행할 때listup필드로 설정돼 있어야 합니다.- format의 형식은 Java, Decimal Format을 사용합니다.
ORDER
데이터를 정렬합니다.
| 옵션 | 기능 |
|---|---|
| key | 정렬할 필드를 선택합니다. |
| sort | 정렬한 direction을 설정합니다. (asc 또는 desc) |
| rows | 같은 시간 값을 가지는 데이터를 최대 몇 개 남길지 설정합니다. default 10000 |
-
key,sort,rows를 설정하는 경우CATEGORY app_counter
TAGLOAD
SELECT [time, pname, host_ip, pid, httpc_count]
ORDER {key: [pid, host_ip, httpc_count] , sort: [desc, desc, desc], rows:2} -
두 번에 나누어서 정렬하는 경우
CATEGORY app_counter
TAGLOAD
SELECT [time, pname, host_ip, pid, httpc_count]
ORDER {key: [pid, host_ip, httpc_count] , sort: [desc, desc, desc], rows:1000}
ORDER {key:tps, sort:desc}
데이터에 time 필드이 포함되는 경우에는 ORDER의 key에 time이 포함되어 있지 않아도 time이 정렬의 최우선 기준이 됩니다.
JOIN
JOIN 명령어에 대한 설명에 앞서 join의 개념을 알아 보겠습니다. join은 두 쿼리문의 결과를 합쳐서 확인하기 위해서 이용합니다. 이 때 두 쿼리의 결과 중 어떤 필드를 기준으로 합칠지에 대한 정보를 전달해야하며 이 필드를 pk 또는 primaryKey라고 합니다.
| Time | Oid | Fields | |||
|---|---|---|---|---|---|
| 2021-06-30 15:30:00 | 2031382584 | field_name_1 | field_name_2 | field_name_3 | field_name_4 |
| sampleData | 123 | 2.543 | testData | ||
| Time | Oid | Fields | |||
|---|---|---|---|---|---|
| 2021-06-30 15:30:00 | 2031382584 | field_name_4 | field_name_5 | field_name_6 | field_name_7 |
| testData | myData | testData | myData | ||
| Time | Oid | Fields | ||||||
|---|---|---|---|---|---|---|---|---|
| 2021-06-30 15:30:00 | 2031382584 | field_name_1 | field_name_2 | field_name_3 | field_name_4 | field_name_5 | field_name_6 | field_name_4 |
| sampleData | 123 | 2.543 | testData | myData | testData | myData | ||
표1과 표2는 쿼리의 결과를 나타내며, pk로 설정한 file_name_4 필드는 파란색으로 표시되어 있습니다. 표3은 pk로 설정한 file_name_4를 기준으로 두 쿼리의 결과가 합쳐진 모습입니다.
두 MXQL에서 조회한 데이터를 합쳐서 볼 수 있습니다. RENAME 명령어와 INJECT 명령어는 JOIN 명령어를 수행한 결과를 가공하는 과정으로 join의 동작에는 영향을 미치지 않습니다.
- 첫 번째 쿼리 : CATEGORY agent_list FLEXLOAD
- 두 번째 쿼리 : /app/act_tx/act_tx_oid
CATEGORY agent_list
FLEXLOAD
JOIN {query:'/app/act_tx/act_tx_oid', pk:oid, field:[act0,act3,act8, act] }
RENAME {src:[act0, act3, act8, act], dst:[normal, slow, verySlow, total]}
INJECT default
샘플 쿼리의 결과 예시는 다음과 같습니다.
| Time | Oid | Fields | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 2021-06-30 15:30:00 | 2031382584 | pcode | pname | ... | type | act0 | act3 | act8 | act |
| sampleData | 123 | ... | testData | 0 | 1 | 0 | 1 | ||
CATEGORY agent_list
FLEXLOAD
JOIN {query:'/app/act_tx/act_tx_oid', pk:oid, field:[act0,act3,act8,act] }
Yard에 저장하는 모든 데이터는 time, oid의 값을 가지고 있습니다. 언제(time) 어떤 에이전트(oid)로부터 수집한 정보인지를 나타내기 위함입니다. 이 필드들도 pk로 사용될 수 있습니다.
JOIN명령어에 사용하는 첫 번째 쿼리는 직접 작성한 MXQL 쿼리, 두 번째 쿼리는 path로 설정할 수 있는 쿼리만 가능합니다.JOIN명령어를 사용한 MXQL 쿼리 전체를 Yard에 파일로 등록해서 사용하면 3개 이상의 카테고리도JOIN할 수 있습니다.
LIMIT
추출하는 데이터의 수를 제한합니다. 앞에서부터 설정한 수만큼의 데이터를 다음 단계로 전달합니다.
가장 먼저 추출된 데이터 3개를 출력합니다.
CATEGORY app_counter
TAGLOAD
LIMIT 3
SKIP
이전 단계로부터 전달받은 데이터 중 일부 데이터를 무시합니다.
1~5번째 데이터는 제외되고 6번째부터 10개의 데이터를 보여줍니다.
CATEGORY app_counter
TAGLOAD
SKIP 5
LIMIT 10
FILTER-KEYS
특정 데이터를 가지고 있는 데이터만 추출합니다.
CATEGORY app_counter
TAGLOAD
FILTERKEYS {keys : [oid], values : [497765289]}
key, value가 아닌 keys, values입니다. 복수형 s에 주의하세요.
FIRST-ONLY
특정 데이터(쌍)을 가진 첫 데이터만 다음 단계로 전달합니다.
CATEGORY app_counter
TAGLOAD
FIRST-ONLY {key:oid}
CATEGORY app_counter
TAGLOAD
FIRST-ONLY {key: [httpc_count, type]}
SELECT [httpc_count, type]
CATEGORY app_counter
TAGLOAD
FIRST-ONLY [httpc_count, type]
SELECT [httpc_count, type]
데이터 로드 단계에서 {backward : true}를 사용했다면 본 명령어의 결과가 달라질 수 있습니다.
TIME-FILTER
특정시간의 데이터를 SKIP할때 사용합니다.
| 옵션 | 기능 |
|---|---|
| time | yyyy/MM/dd HH:mm:ss로 설정합니다. 설정한 시간 기준 duration:1000을 설정합니다. (설정한 시간 기준 1000ms동안의 데이터 제외) |
| date | yyyy/MM/dd로 설정해야합니다. 설정한 시간 기준 duration:d1과 같이 설정합니다. (설정한 시간 기준 하루동안의 데이터 제외) |
| duration 또는 dur | 필터링 범위를 설정합니다.(d1: 1일, h1: 1시간 , m1, m5, m10: 1분, 5분, 10분 , number: millisec) |
| timezone | 데이터 타임존을 설정합니다. (예시, 'GMT9') |
| gmt | 데이터 타임존을 설정합니다. (예시, 9 또는 -9) |
CATEGORY app_counter
TAGLOAD
TIME-FILTER { date:'2020/07/28' , timezone:'GMT9'}
CATEGORY app_counter
TAGLOAD
TIME-FILTER {time:'2021/06/22 00:00:00', gmt:9 }
INJECT
해당 위치에 MXQL 쿼리를 추가합니다.
default 위치에 inject될 MXQL 쿼리를 전달해야 합니다.
CATEGORY app_counter
TAGLOAD
SELECT
INJECT default
ROWNUM
프론트 단에서 INJECT 명령어의 오퍼랜드에 맵핑될 정보를 전달해주어야 합니다. 다음 예제는 키가 default로 설정된 값을 추가합니다.
사이트 맵 > MXQL 데이터 조회'에서 INJECT 값 전달하는 예시
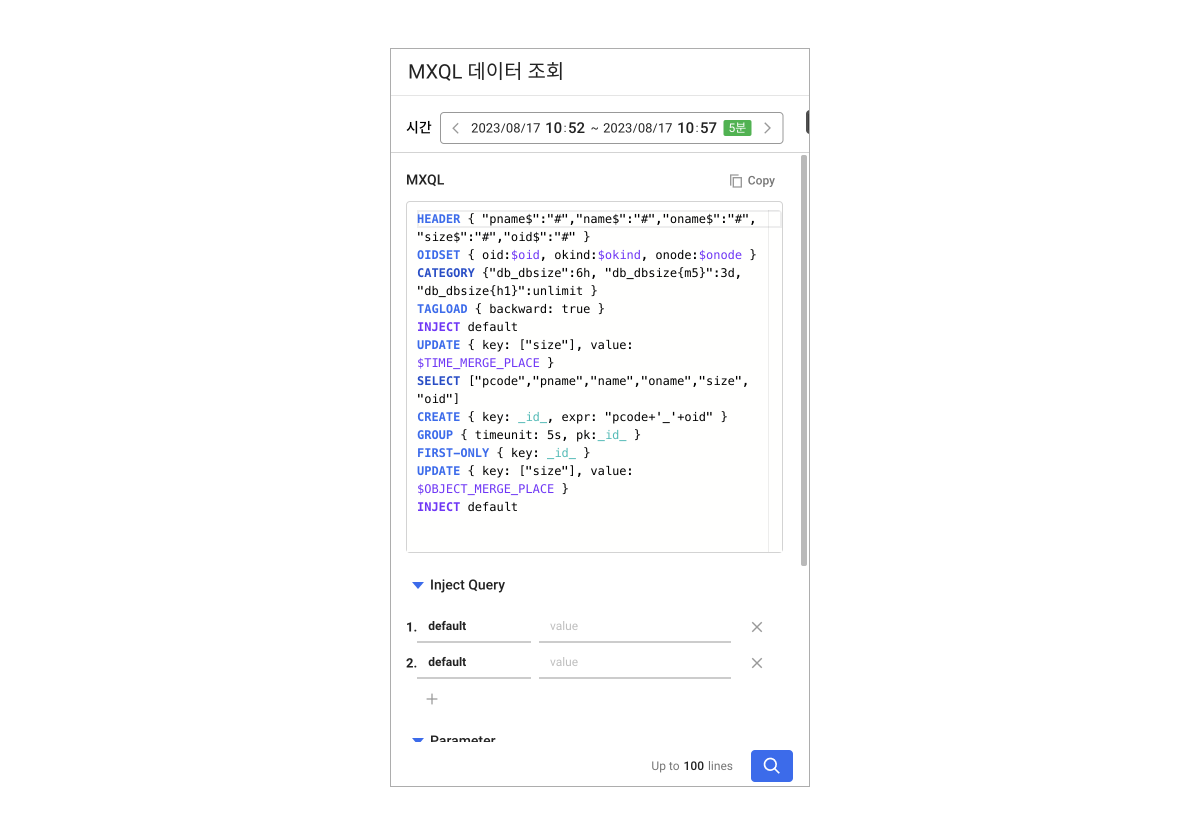
ADJUST
숫자 필드의 값을 변경하기 위해 사용합니다. (time 값은 변경할 수 없습니다.)
| 옵션 이름 | 옵션 기능 |
|---|---|
| add | 모든 숫자 데이터에 값을 더합니다. |
| sub | 모든 숫자 데이터에 값을 뺍니다. |
| mul | 모든 숫자 데이터에 값을 곱합니다. |
| div | 모든 숫자 데이터에 값을 나눕니다. |
| over | 모든 숫자 데이터에 최소값을 설정합니다. |
| under | 모든 숫자 데이터의 최대값을 설정합니다. |
-
mul을 설정하는 경우CATEGORY app_counter
TAGLOAD
SELECT
ADJUST {mul : 100} -
over를 설정하는 경우CATEGORY app_counter
TAGLOAD
SELECT
ADJUST { key:[rate], over:30}
-
under를 설정하는 경우ADJUST { key:[rate], under:30}
FILTER
특정 조건을 가지고 있는 데이터만 다음 단계로 전달합니다.
| 옵션 이름 | 옵션 기능 |
|---|---|
| expr | 조건을 수식으로 입력합니다. |
| value | 특정 값을 가지고 있는 데이터를 찾습니다. |
| exist | 값이 있는 데이터를 찾습니다. |
| notexist | 값이 없는 데이터를 찾습니다. |
| over | 특정 값보다 같거나 큰 데이터를 찾습니다.(greater 또는 equal to) |
| under | 특정 값보다 같거나 작은 데이터를 찾습니다.(less 또는 equal to) |
-
expr옵션을 적용하는 경우CATEGORY app_counter
TAGLOAD
SELECT
FILTER {expr : "tx_count != 0"} -
value옵션을 적용하는 경우CATEGORY app_counter
TAGLOAD
SELECT
FILTER { key : tx_count, value : 5} -
exist옵션을 적용하는 경우CATEGORY app_counter
TAGLOAD
SELECT
FILTER { key : tx_count, exist : true} -
notexist옵션을 적용하는 경우CATEGORY app_counter
TAGLOAD
SELECT
FILTER { key : tx_count, notexist : true} -
under옵션을 적용하는 경우CATEGORY app_counter
TAGLOAD
SELECT
FILTER { key : tx_count, under : 6}
- 데이터가 0인 경우도 데이터가 존재하는 경우입니다.
{exist: true}에 적용됩니다. {exist : false}와{notexist : false}는 불가능합니다.{notexist : true}와{exist : true}를 사용해주세요.