ネットワーク性能モニタリング
ネットワーク性能モニタリング(Network Performance Monitoring、以降NPM)は、ネットワーク間の混雑および障害を把握し、ユーザーのネットワーク性能改善に活用するためにプロセスのネットワーク通信情報を収集し、可視化するソリューションです。
ネットワーク性能モニタリングの必要性
ネットワーク環境の変化
ネットワークモニタリングは、既存の機器中心のモニタリングからプロセス中心のモニタリングに変化する必要があります。 既存のネットワークモニタリングは、サーバーおよびネットワーク機器に従属的な情報をSNMPプロトコルを通じて取得して、可視化する方法で動作します。 最近、ネットワーク市場はクラウドと仮想化という大きな枠組みで成長しており、これにより既存のモニタリング方式では障害の状況や要素を判断しづらくなっています。
-
クラウド
サーバーおよびネットワーク機器を構成してサービスを運営していた既存のオンプレミス(On-premise)環境から、クラウドサービスプロバイダ(CSP)が提供する仮想環境上でサービスを運営する形に変化しています。 物理的な実体がないクラウド環境での重要なモニタリング対象は、実際に作業を遂行するプロセスです。
-
仮想化
コンテナベースの仮想化環境では、複数のコンテナが1つの機器で実行されます。 各コンテナは独立したネットワークスタックを持ち、1つの機器でも複数のコンテナ間の通信が存在します。 既存の機器ベースのネットワークモニタリングでは、問題が発生したコンテナおよびプロセスまで区別することは困難です。
Network Function Virtualization(NFV)を通じて、別途のH/Wで具現された既存のネットワーク機能をソフトウェアで仮想化させる努力も続いています。
既存のネットワーク性能モニタリング方式では、クラウドと仮想化によって追跡できないグレーゾーンが発生するようになりました。 WhaTapのNPMはプロセスを対象に、ネットワーク動作を追跡するため、クラウドと仮想化に対する環境変化に対応できます。
ネットワーク複雑性の増加
Micro Service Architecture(MSA)ベースのサービスが増えており、特有の柔軟性と拡張性によってネットワーク関係が複雑になっています。 高可用性(High Availability、HA)構成やScale Outなど、サービス安定化のために行う作業もネットワークの複雑さに影響を与えています。 関係が複雑になるにつれ、負荷発生の有無を認識し、負荷区間を把握する過程がますます難しくなっています。
WhaTapのNPMは、各プロセスが実行するネットワーク動作を追跡し、複雑なコンポーネントと状態情報をトポロジーを通じて直感的に理解できるように可視化します。
期待効果
プロセス単位で収集される指標を通じて、次の効果が期待できます。
-
プロセス単位のネットワーク指標モニタリング
-
サービス従属性の把握と改善
-
ネットワークコストの最適化
-
ネットワークトラブルに対するMTTD、MTTRの減少
-
MTTD(Mean Time To Detect): トラブル発生を検出するまでの時間
-
MTTR(Mean Time To Repair): トラブル発生を検出した後、復旧までにかかった時間
-
主な特徴
複雑なネットワークをグループ化して、区間別のパフォーマンス指標をすばやくモニタリングできます。 トポロジーダッシュボードを通じてネットワークの状況をリアルタイムでモニタリングができるし、タグルール設定機能でネットワーク情報をグループ化および簡素化させることで、ネットワークの障害区間をより素早く把握できます。
-
安定的で詳細なデータ収集
WhaTap NPMでは、eBPF技術を活用してデータを収集します。 eBPFは、カーネルで発生する様々なイベントを収集し、サンドボックス環境で追加的な動作を実行できる技術です。 カーネルのイベントを収集するので、プロセスレベルの詳細な情報が取得でき、サンドボックスベースで動作するため安定した運用が可能です。
-
タグルール設定による可視性の確保
ネットワークモニタリングは、さまざまで複雑なネットワークのデータを簡単に理解できるような方法を提供しなければなりません。 WhaTap NPMは、ユーザーの目的と意図に応じてネットワーク要素を表現できるようにタグルール設定機能をサポートします。 ユーザーサービスの特性に合わせて様々なカスタマイズが可能です。
-
Raw Dataによるトラブルシューティング
サーバーに接続しなくても、障害状況が解消された後も、特定時点でネットワーク状態をメトリクス基準で確認でき、関連するサーバーやプロセスなどの問題把握をサポートします。
ノートRaw Dataを活用するメニューの詳細については、次の文書を参照してください。
-
Flexボードによる様々な基準のカスタムチャート
収集された情報を通じて、様々な基準でカスタムチャートを作成できます。
主な指標の案内
5つのネットワーク指標を介してネットワーク性能をモニタリングします。
-
品質指標
LatencyとJitter指標を提供し、性能問題およびトラブルの有無を判断する基準として利用します。 TCPベースのネットワーク通信を活用するケースから収集が可能です。
-
Latency: ネットワーク応答時間を意味する指標です。 応答時間の高い区間は、最終ユーザーに良くない経験を与える可能性があります。
-
Jitter: ネットワーク応答時間の変動性を意味する指標です。 Jitter値が高いという意味は、当該区間のネットワーク混雑、パケット移動経路の変化が頻繁に発生するという意味に解釈できます。 特定ネットワーク区間にトラブルが存在する可能性があります。またパケット到着の順番がねじれてパケット再送信およびロスが発生し、サービス品質の低下につながります。
-
-
ネットワーク使用量の指標
bps、pps、session countの3つの基準でネットワーク使用量に関する情報を提供し、意図していない外部トラフィックの流入(DDoSなど)やトラフィックパターンなどを通じて、クラウド環境を最適化するのに活用できます。
-
bps: bits per second(bps)は、毎秒伝送bit数を示す指標です。
-
pps: packets per second(pps)は、毎秒の提出パケット数を示す指標です。
-
session count: ユニークなセッション数を示す指標です。
-
指標活用の案内
-
ネットワーク指標はサーバーのCPU使用量と同様に、ユーザーの目標しきい値があることをお勧めします。
-
サービス信頼性のためにSLI(サービスレベル指標)、SLO(サービスレベル目標)を定義し、これをベースに一定水準のサービスを着実に提供できなければなりません。
-
もし目標値が不明な場合は、WhaTapが提供する初期基準でデータを収集し、その後目標を設定してサービスの改善を試みてください。
-
-
現在のWhaTapでは、デフォルトのしきい値を次のように適用します。 ユーザー環境およびSLO目標値に合わせて変更できます。
-
Jitter: 30ms
-
Latency: 200ms
-
bps: 128Mib/s
-
pps: 50k
-
session count: 100
-
-
トポロジーにしきい値を適用して、しきい値を超えた区間をすばやく把握し、改善するかどうかの判断をサポートします。
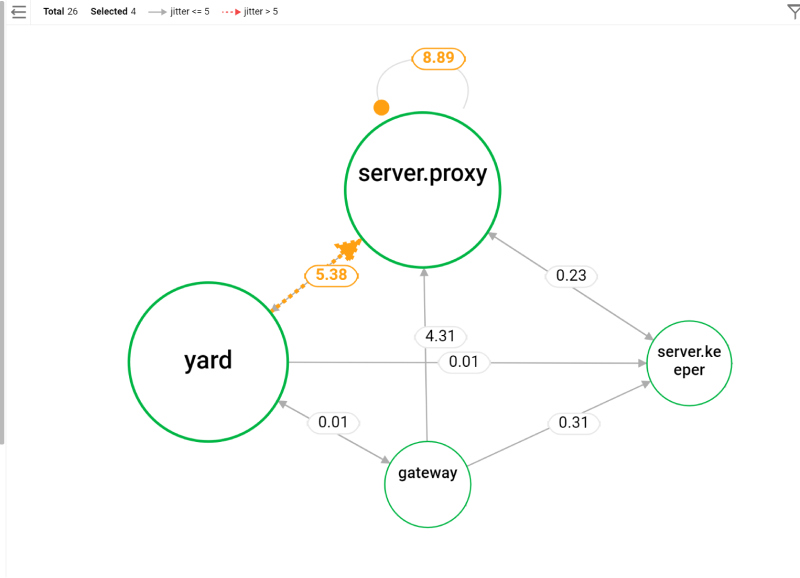
-
各指標がしきい値を超えた時点で通知を送り、そのイベント情報を確認できます。
-
ネットワーク指標は、一般的な状況で平らな水平形態のチャートを期待しています。 平均値から急激に変化する指標を通じて、トラブルの有無を判断し、区間を識別できます。