Pod起動分析
ホーム画面 > プロジェクト選択 > 分析 > Pod起動分析
WhaTapノードエージェントバージョン1.4.2以降に対応します。 当該バージョン未満の場合、既存メニュー(旧Pod初期化性能) 画面を提供します。
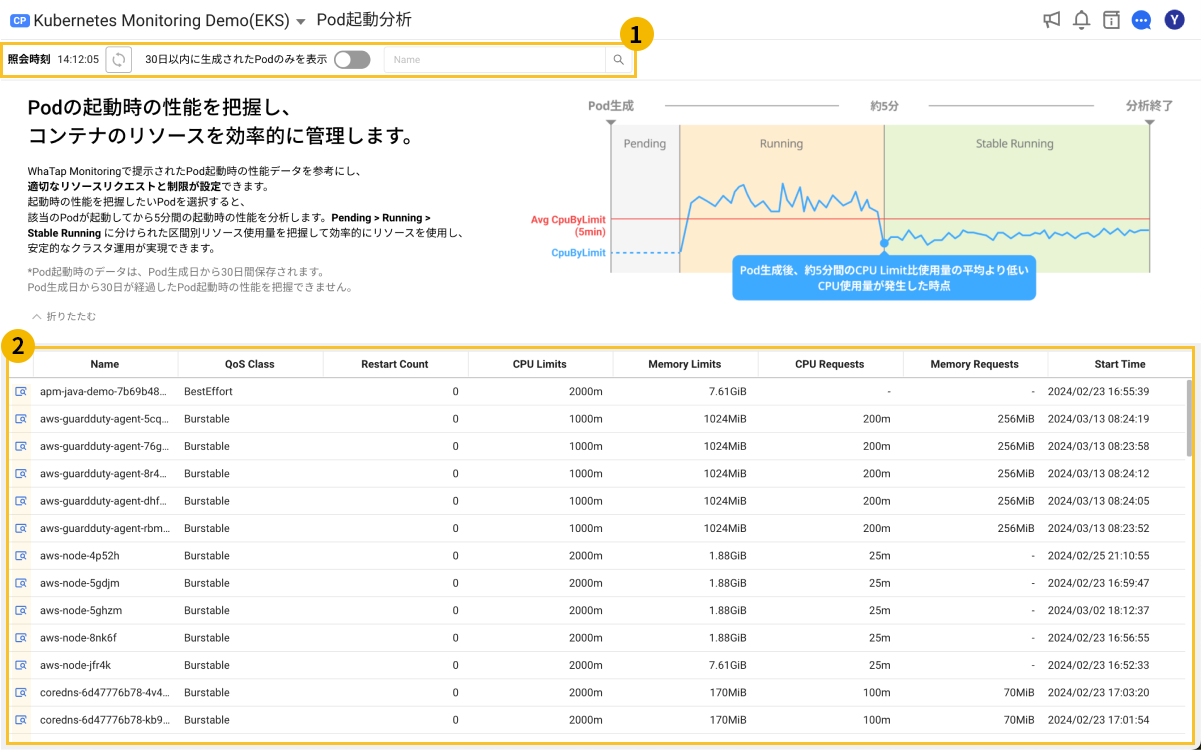
円滑なクラスター運用のために、Podが安定的に動作するまでの性能を分析し、Podに割り当てられたリソースのサイズを最適化する必要があります。 Pod起動分析メニューは、Podが起動してから約5分間の変化を追跡します。 Pending状態からRunning状態に、そして安定的なStable Running状態につながる3段階のリソース使用量を分析することにより、リソース割当量を最適化できます。
これにより、運用者は、リソース効率の向上とコストの削減、スケーラビリティの向上、スケールの容易性などの利点を得ることができます。
基本画面ガイド
上段オプション領域
上段の![]() 領域で以下のオプションを活用できます。
領域で以下のオプションを活用できます。
-
 更新アイコンを選択して
更新アイコンを選択して 領域のPod領域を再度読み込むことができます。
領域のPod領域を再度読み込むことができます。 -
30日以内に生成されたPodのみ表示
 トグルを活性化して領域のPod一覧で30日以内のPodだけを照会できます。ノート
トグルを活性化して領域のPod一覧で30日以内のPodだけを照会できます。ノートPod開始分析メニューは、Pod生成日から直近30日以内の範囲内で5分間のPod開始データを分析します。 つまり、生成後30日が過ぎたPodの場合、開始性能を分析できません。
-
Pod検索の入力欄に文字を入力してPodを検索できます。
Pod一覧領域
![]() 領域でPod一覧を確認できます。 Pod一覧が開いたテーブルのヘッダーカラムには、次の情報が含まれています。
領域でPod一覧を確認できます。 Pod一覧が開いたテーブルのヘッダーカラムには、次の情報が含まれています。
-
QoS Class:PodのQuality of Serviceを意味します。 QoSクラスは、リソース不足時のPodの優先順位を決定します。 優先順位の高いPodが優先順位の低いPodより先に終了します。
-
Guaranteed: ノードで使用可能なリソースが保証され、他のPodよりも優先的に割り当てます。 最後に終了します。
-
PodのすべてのコンテナがCPUおよびメモリのrequestを持っている場合です。
-
PodのすべてのコンテナがCPUおよびメモリに limitを持っており、それらの値がrequestと同じである場合です。
-
-
Burstable: Podはノードのリソースが不足している場合は、一部のリソースを割り当てます。
-
Guaranteedクラスの条件を満たしていない場合です。
-
PodのコンテナのいずれかがCPUおよびメモリに request または limitが設定されている場合です。
-
-
BestEffort: リソース requestやlimitがないため、他のPodより優先度が低くなります。 最初に終了します。
- Podのすべてのコンテナには、CPUおよびメモリの requestと limitはありません。
-
-
Restart Count:Pod内コンテナの総再起動回数です。
-
CPU/Memory Limits: Pod内コンテナに設定されたCPU/Memory Limitsの総合(
resources.limits)です。 -
CPU/Memory Requests: Pod内コンテナに設定されたCPU/Memory Requestsの総合(
resources.requests)です。 -
Start Time: Pod生成時刻(
metadata.startTime)です。
詳細表示の案内
![]() 領域のPod一覧で分析を希望する項目の一番左の
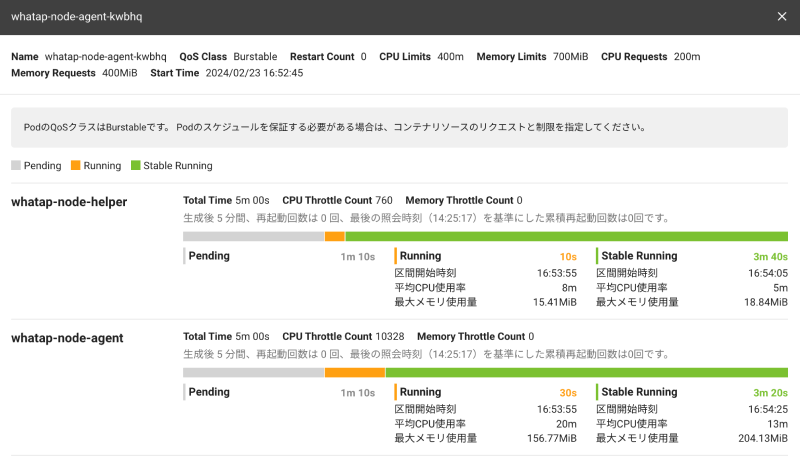
領域のPod一覧で分析を希望する項目の一番左の![]() 詳細を見るボタンを選択します。 選択したPodのコンテナ別の開始性能を区間別に分析した内容を次のように確認できます。
詳細を見るボタンを選択します。 選択したPodのコンテナ別の開始性能を区間別に分析した内容を次のように確認できます。
-
Pending: Podを生成した後Running状態に進入する区間です。
-
Running: PodがPending状態を経て安定化するまでの区間です。
-
Stable Running: PodがRunning状態を経て安定化した区間です。
安定化した状態(Stable Running)
WhaTapでは、Pod生成直後の約5分間、コンテナのCPU Limit比使用量の平均を計算します。 この平均値よりCPU使用量が少なくなる時点を安定化の開始状態と定義します。
詳細分析する
-
5分間に1つのコンテナが何度も再起動した場合は、最初に開始したコンテナの情報のみを表記します。 コンテナごとの再起動回数を確認してください。 再起動の回数が多い場合は、そのコンテナが正常に実行されていることを確認してください。

-
Pending区間が長いなら、PodがRunning状態に進入するまで長い時間がかかったという意味です。 PodのPending状態を誘発する要因があるか点検してみてください。
ノートPodのpendingステータスの詳細については、次のリンクを参考にしてください。
-
Running区間が長いなら、Pod内のコンテナが初めて実行される時、リソース使用量が多い区間があるという意味です。 コンテナの実行過程に問題がないか確認してください。
-
全体的な初期リソース使用量が多い場合は、コンテナリソースのリクエストと制限を増やすことを検討してください。