リソースボードを見る
この文書では、WhaTapモニタリングサービスの一つであるサーバモニタリングのリソースボードメニューのチャート型ウィジェットに対する分析方法を説明します。サーバー(Server)の問題をリソースボードで特定して分析する方法を説明します。リソースボードの機能の概要については、次の文書を参照にしてください。
サーバーモニタリングの核心はプロセスです。プロセスが通常の動作範囲内で中断することなく動作できるためには、サーバーの状態をいち早く把握し、さまざまなトラブルに対応しなければなりません。リソース使用量をチェックしながら予想するのがその始まりです。WhaTapのリソースボードは、データ集約型の画面でリソース使用量を一目で確認できるように、CPU、Memory、Disk、Network関連の指標で構成された時系列チャートウィジェットが用意されます。
-
サーバー状態の概要:Server、 OS、 Total Cores、 Avg CPU、 Avg Memory、 Avg Disk、 Server Status Map
-
システム動作統計:CPUResourceMap
-
早期警報及び通知:CPU TOP5、Memory TOP5、Disk I/O TOP5、プロセスCPU TOP5、リアルタイムアラート
サーバモニタリングの主なメトリクス
-
CPU:CPUのパフォーマンス指標は、サーバのパフォーマンスを把握するための最も重要な指標として使用します。CPUの使用率が一定のレベルを超えると、サービスに影響します。問題が発生した場合、ハードウェアの追加購入やCPUを使用するアプリケーションのパフォーマンスをチューニングするなど、CPUの使用率の管理目標を達成するための対策を講じられます。
ノートIT関連のソリューションは、サーバーのパフォーマンスに基づいて価格設定があります。それらのほとんどが、CPUのコアに基づいて価格が設定されているのと同じ理由です。
-
Memory:バッファおよびキャッシュメモリなどのメモリの使用状況を確認します。メモリの使用量が急に高くなったり、高いまま持続的に低下されない場合は、メモリ使用量の管理目標を達成するための対策を講じられます。
-
Disc I/O:DiskI/Oはネットワークドライブを使用しているかどうかを確認する必要があるモニタリング要素です。ディスクの読み取り速度、書き込み速度、キュー、待機時間などをモニタリングします。
-
Network:ネットワーク指標は、ネットワークインターフェースの入出力トラフィックの速度とエラーパケットなどをモニタリングします。
サーバステータスの概要

ユーザーはリソースボードの上部にある情報パネルからプロジェクトに登録されているサーバー全体の概要指標を簡単に確認できます。
Serverウィジェットですべてのサーバー数と障害が発生したサーバー数を確認できます。![]() ボタンを選択すると、サーバーリストメニューに移動します。状態カラムからすぐ対応が必要な
ボタンを選択すると、サーバーリストメニューに移動します。状態カラムからすぐ対応が必要な![]() 危険(赤色)、トラブル発生の可能性がある
危険(赤色)、トラブル発生の可能性がある![]() 警告(オレンジ色)、正常動作範囲である
警告(オレンジ色)、正常動作範囲である![]() 通常(緑色)、データが収集されてない
通常(緑色)、データが収集されてない![]() 非活性(グレー)の状態が、アイコンと色で簡単に確認できます。サーバーリストの詳しい説明は次の文書を参照にしてください。
非活性(グレー)の状態が、アイコンと色で簡単に確認できます。サーバーリストの詳しい説明は次の文書を参照にしてください。
OSウィジェットはプロジェクト内のOS数、Total Coresはサーバー全体コアの合計、Avg CPUはサーバー全体CPUの平均使用率、Avg Memoryはサーバー全体メモリの平均使用量を表します。
リソースボード中央メインチャートの![]() アイコンを選択して、ServerStatusMapに移動すると、ハニカムチャートからプロジェクト内サーバーのステータスを一目で確認できます。ハニカムチャートビューは、サーバーが多数の場合に便利です。1つの六角形が、1つのサーバーエージェントを意味します。問題が発生したサーバーを色で可視化し、直感的に識別が可能です。個々の六角形を選択すると、サーバーエージェントのサーバー詳細ページに移動します。
アイコンを選択して、ServerStatusMapに移動すると、ハニカムチャートからプロジェクト内サーバーのステータスを一目で確認できます。ハニカムチャートビューは、サーバーが多数の場合に便利です。1つの六角形が、1つのサーバーエージェントを意味します。問題が発生したサーバーを色で可視化し、直感的に識別が可能です。個々の六角形を選択すると、サーバーエージェントのサーバー詳細ページに移動します。

WhaTapのリソースボードの各ウィジェットを使用して、リソース使用量の全体とサーバーの状態の概要を簡単に確認できます。
システム運用統計
プロセスの正常動作を確認するための最も重要な要素はCPUの使用率です。CPU指標がシステムの負荷状況をすぐ反映するためです。WhaTapは、システム全体の状況を一目で確認できるようCPU使用率を分布図チャートとして提供します。リソースボード中央の![]() アイコンを選択すると、CPU resource mapが表示されます。CPU resource mapでは、プロジェクト内のサーバー全体のCPU使用率の分布図を確認できます。セル領域をドラッグすると、該当セッションの詳細情報が表示されます。
アイコンを選択すると、CPU resource mapが表示されます。CPU resource mapでは、プロジェクト内のサーバー全体のCPU使用率の分布図を確認できます。セル領域をドラッグすると、該当セッションの詳細情報が表示されます。
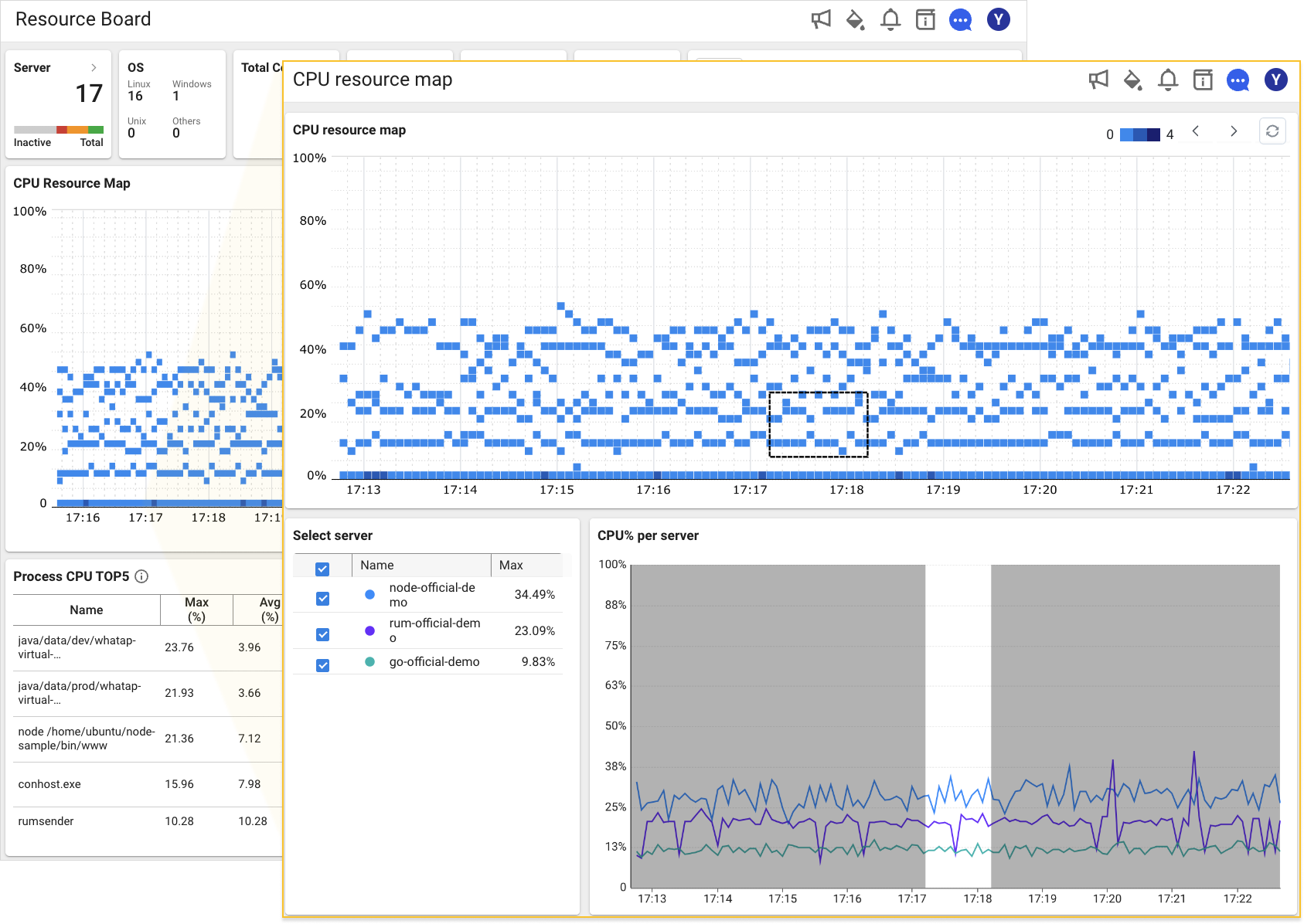
クラウドIT資産を効率的に運用するには、リソースの過剰な状態と過不足の状態を両方を回避し、使用量を適切に制御することが必要です。次の画面では、操作を最適化することでリソース使用量を50%にして、コストおよびパフォーマンス効率のバランスを取ろうとします。このような例の場合、使用量が増加した時に50%のパフォーマンスマージンを使用して一時的なトラブルを回避できます。
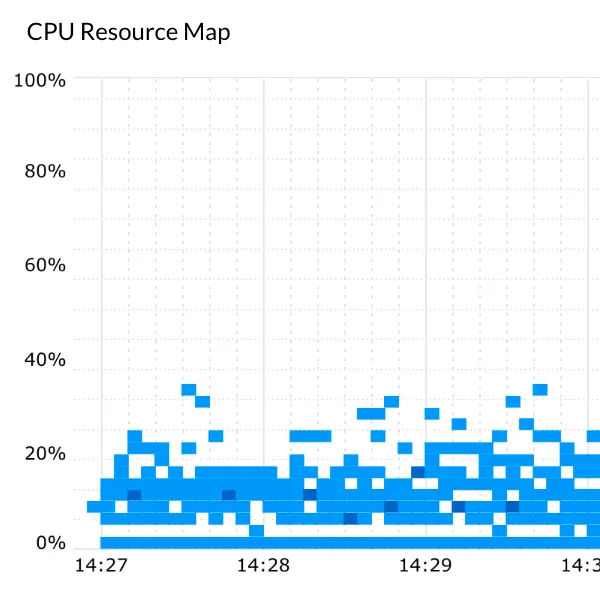
過剰投資とは、サービスと比較してシステムが過剰にインストールされ、インフラコストが必要以上に支出されている状態です。システムの安定性が保証されているため、ユーザーがピーク時に受ける影響は大きくありません。その結果、モニタリングに費やす時間を短縮すために、使用量の平均値を下げることで過剰投入する傾向があります。ただし、過剰投入の傾向が高まるとコストが増加するため、状況をすばやく知ることが重要です。過少投入とは、システム変更などによる負荷の増加によりシステムの利用が制御不能となり、サービス品質の低下やユーザビリティの低下を招きます。ユーザーがサービスから離れる前に、適切なアクションが必要です。
WhaTapのCPU Resource Mapを使用すると、過剰投入と過少投入の状況を簡単に特定して確認できます。マップの下部は一般的に過剰投入傾向にあり、上部は過少投入傾向にあります。
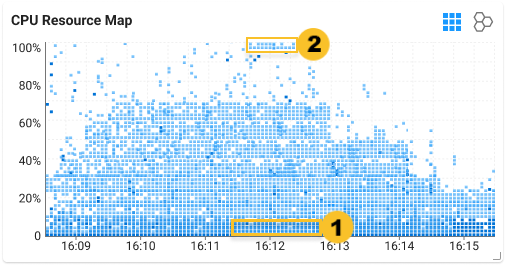
サンプル画面CPUResourceMap下部にある![]() エリアをドラッグして詳細情報を表示すると、サーバーあたりのCPU使用率グラフで過剰投入の傾向が確認できます。
エリアをドラッグして詳細情報を表示すると、サーバーあたりのCPU使用率グラフで過剰投入の傾向が確認できます。
これは高い傾向性を提示したもので、下部に表示されるサーバーがすべて過剰投入の状態ではありません。定期的に負荷がピークになるサーバーの場合、チャートの解析に注意する必要があります。
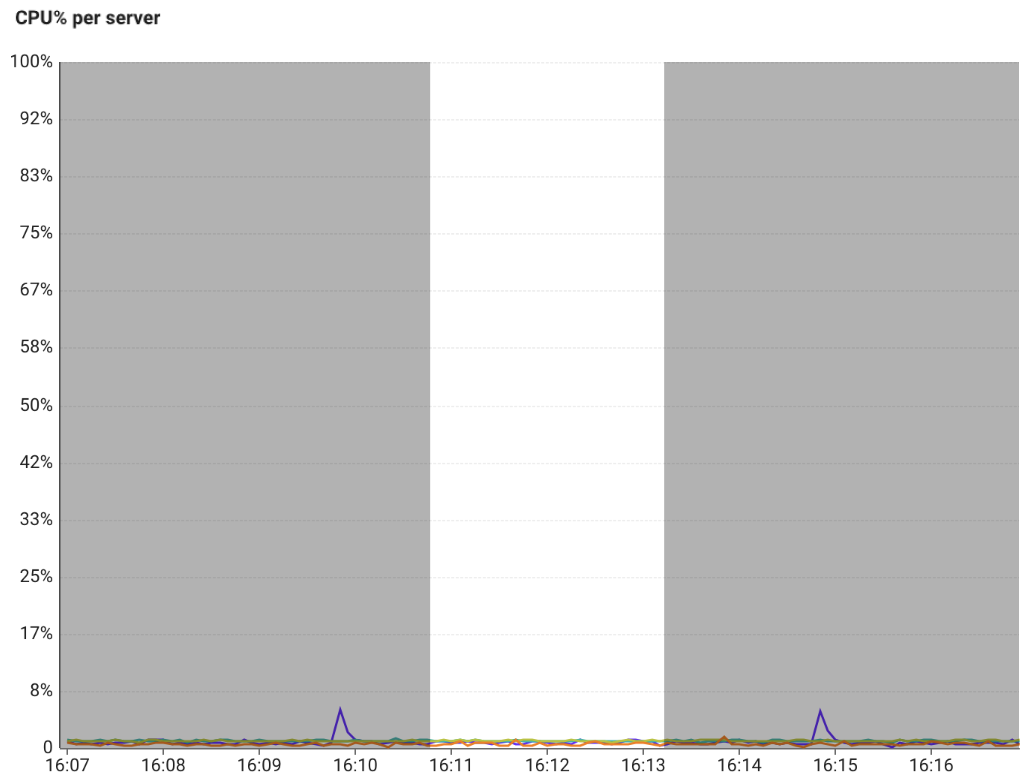
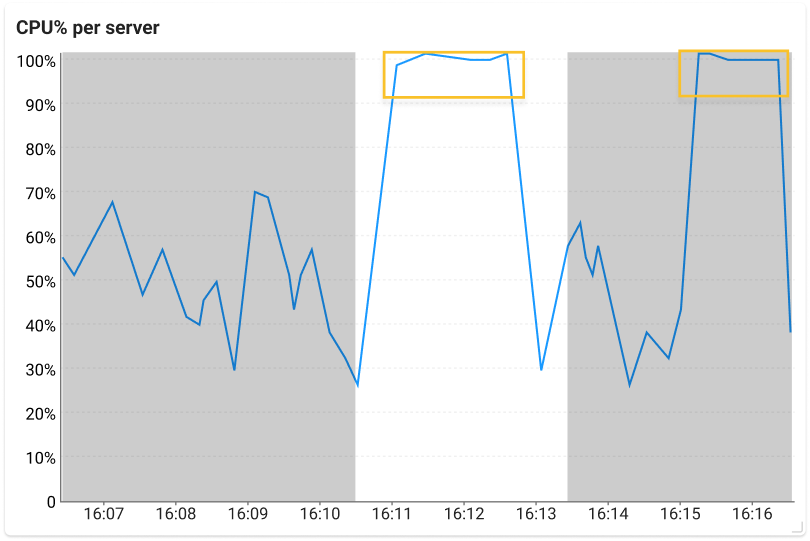
CPU Resource Map上段の![]() エリアをドラッグして詳細情報を表示すると、サーバーあたりのCPU使用率グラフで過小投入の傾向を確認できます。次の詳細情報の例は、一般的なCPU低下または、Starvation状態の画面であり、サーバーはピークと解像度が繰り返されてクリティカルです。
エリアをドラッグして詳細情報を表示すると、サーバーあたりのCPU使用率グラフで過小投入の傾向を確認できます。次の詳細情報の例は、一般的なCPU低下または、Starvation状態の画面であり、サーバーはピークと解像度が繰り返されてクリティカルです。
IT資源は、効率と改善のために常に見直す必要があります。WhaTapのサーバーモニタリングは、異常な状態をすばやく特定し、プロセスをすぐに表示できるように エンジニアのノウハウを可視化しました。CPU ResourceMapを使用してリソースの過剰状態と過不足状態を簡単に識別できるだけでなく、次に説明するリソース使用状況の上位5つの一覧ウィジェットで主要なプロセスが一目で確認できます。複数のプリセットを必要とする不要なチャート構成を減らし、データ集約型のWhaTapのダッシュボードを使用して、コミットの過不足および主要なプロセスをすばやく表示します。
早期アラートおよび通知
WhaTapのリソースボードは、リソース使用率が最も高いサーバーとプロセスの上位5つの一覧チャートを提供します。ユーザーが潜在的に問題のあるサーバーを特定するのに役立つ早期警報ウィジェットは、それぞれ右側と下部で確認できます。
リソース使用率が高い場合、トラブルが必ず発生します。WhaTapは、Top 5のリストチャートを通じてサーバーモニタリングの重要な指標であるCPU、Memory、Disk I/O、Networkなどのリソース使用率が高いサーバーとCPU、Memory使用率が高いプロセスを一目で確認し、トラブルを早期に解決するのに役立ちます。
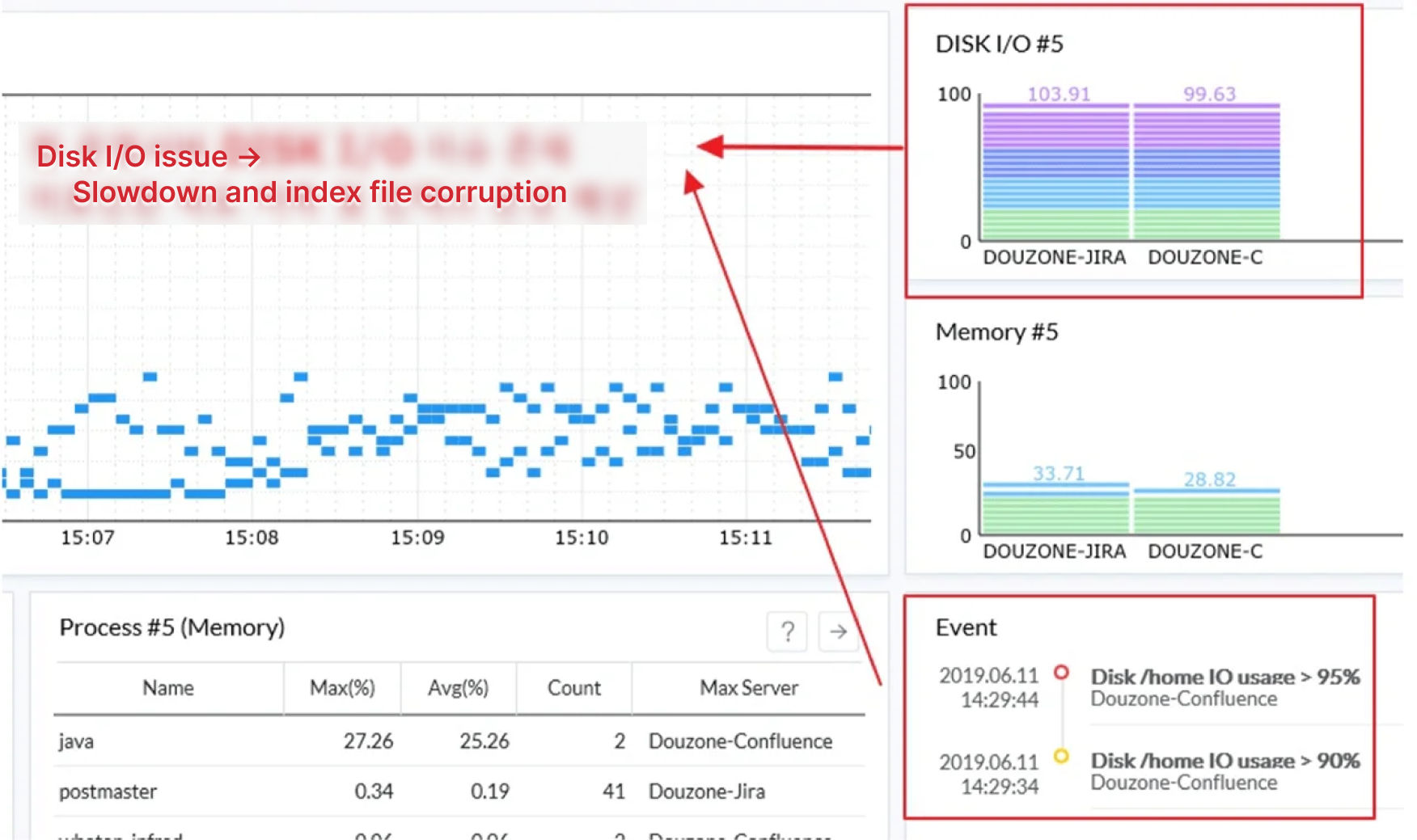
大きな問題が発生する前に、WhaTapのリソースボードを通じてシステムの主要な問題の事例を紹介します。次の画面では、Disk I/O Top5ウィジェットに、使用可能な容量と比較してDisk I/Oが高い機器のステータスを確認できます。
ステータス情報をもとに、同じ機器で発生したトラブル履歴を確認し、速度低下やインデックスファイルの破損などの異常が発生していることを確認しました。そこで、SSDを導入し、大容量で導入が難しい場合、NASスナップショットのバックアップを使用することで、Disk I/Oの問題を解決しました。
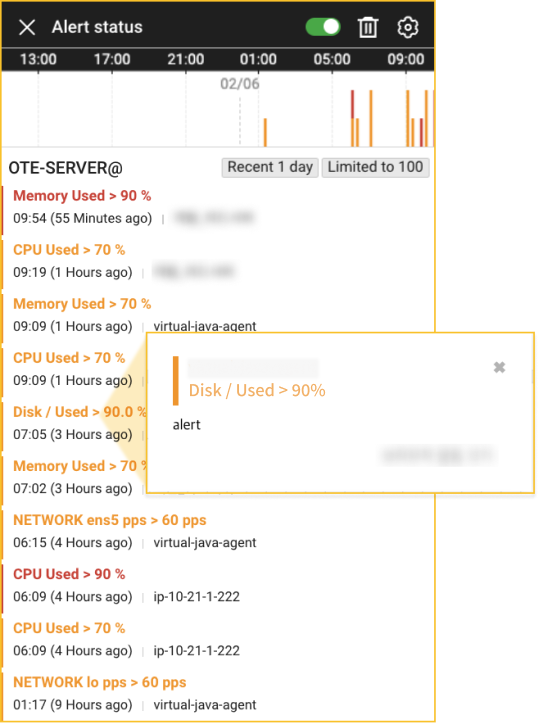
最新のイベントの傾向が確認できるリアルタイム通知はリソースボードの上部にある固定メニューで利用できます![]() ボタンをクリックして確認できます。WhaTapは、独自の通知しきい値設定を提供します。エージェントをインストールしてデータを収集すると、プリセットを必要とせずに、それ以降の通知を確認できます。例えば、Disk I/O(%)指標は5秒間のディスク使用率を表します。Disk I/O(%)が80%を超えるとシステムパフォーマンスに影響を与える可能性がありますが、100%の場合は、ディスクが常時稼働していることを意味します。WhaTapサーバーモニタリングでデフォルトに設定されたDisk I/O(%)のアラート値は90%です。つまり、90%を超える場合は、ユーザーがしきい値の詳細設定していない場合でも、通知がすぐに行われます。
ボタンをクリックして確認できます。WhaTapは、独自の通知しきい値設定を提供します。エージェントをインストールしてデータを収集すると、プリセットを必要とせずに、それ以降の通知を確認できます。例えば、Disk I/O(%)指標は5秒間のディスク使用率を表します。Disk I/O(%)が80%を超えるとシステムパフォーマンスに影響を与える可能性がありますが、100%の場合は、ディスクが常時稼働していることを意味します。WhaTapサーバーモニタリングでデフォルトに設定されたDisk I/O(%)のアラート値は90%です。つまり、90%を超える場合は、ユーザーがしきい値の詳細設定していない場合でも、通知がすぐに行われます。
WhaTapのデフォルトの通知設定により、ユーザーはエージェントがインストールされるとすぐにモニタリングが開始されます。WhaTapサーバーモニタリングの特長である効率と利便性を反映します。簡単に設定できるプロセス通知など、サーバーモニタリング通知設定の詳細については、次の文書を参照ください。
リソースボードはサーバー全体のステータスを要約し、簡潔で問題志向のビューを提供する効率的なダッシュボードです。CPUに問題が存在するサーバーの数と傾向を同時に検知するためのメインチャート(CPU Resource Map)とOSモニタリングの主要指標によるTop5の一覧を通じて問題を引き起こしそうなターゲットリソースを公開し、サーバーで発生した通知履歴を最新の順序で表示します。WhaTapの直感的で簡潔なダッシュボード構成は、大規模なシステムをモニタリングする必要がある場合にさらに役立ちます。
ダッシュボードの追加
- リソース別のTop5ウィジェットの
 ボタンをクリックすると、リソースイコライザーメニューへ移動し、サーバー全体のリアルタイムの使用状況を表示できます。
ボタンをクリックすると、リソースイコライザーメニューへ移動し、サーバー全体のリアルタイムの使用状況を表示できます。 - サーバーユニットの詳細情報は、ウィジェットのチャート領域を選択して移動するサーバー詳細メニューで確認できます。
- サーバーリソースの利用パターンを表示したり、負荷設計と比較する場合は、分析>メトリクスチャートメニューを使用します。