アプリケーションダッシュボードを確認する
この文書では、WhaTapモニタリングサービスの一つであるアプリケーションパフォーマンスモニタリング(Application Performance Monotoring、以下APM)のアプリケーションダッシュボードメニューからチャート型ウィジェットに対する分析方法を紹介します。Webアプリケーションサーバ(Web Application Server)の問題をアプリケーションダッシュボードを使用して、特定及び分析する方法を見てみましょう。アプリケーションダッシュボードの機能については、次のドキュメントを参照してください。
ウェブサービスは多数のアプリケーションとプラットフォームで構成されており、アプリケーションの観点から性能を分析は複雑になります。アプリケーションダッシュボードでは、次の観点から分析できるダッシュボードにウィジェットを追加しました。
- アプリケーション接続のステータス: エージェント
- トランザクション:スピードメーター、アクティブトランザクション、アクティブステータス、ヒットマップ
- サービス: _ Apdex_、TPS、平均応答時間
- リソース:システムCPU、ヒップメモリ
- ユーザー: 同時接続ユーザー
- 1日基準での比較:今日のTPS、今日のユーザー
アプリケーション接続のステータスを確認
アプリケーション ダッシュボード画面の上部に、WhaTapモニタリングサービスに接続されたアプリケーションサーバーを確認できます。接続されたエージェントが非活性化になっているか、アプリケーションサーバーとの通信が切断されている場合は、Inactive項目を確認すると、エージェントの状態を簡単に把握できます。

接続されたエージェントを一行に一覧表示して画面を効率的に使用する場合は、エージェントの名前を短く設定できます。エージェント名を設定する方法の詳細については、次の文書を参照してください。
トランザクション分析

ウェブアプリケーションサーバー(WAS)を使用するユーザーは、ブラウザを使用して要求されたサービス(AP)の結果が正しく実行されることを期待します。サービス(AP)は、正しく動作するためにサーバーのリソースを使用します。 リソースとは、APプロセス、OS/HWリソース(CPU、メモリ、ディスクなど)、外部システム(Database、その他のサーバ) などを意味します。
ユーザーが希望する結果が得られない場合、応答が遅い場合は、障害の発生または、パフォーマンスに問題があります。これは、サービス(AP)のプログラミングの問題である場合または、リソースの問題である可能性があります。アプリケーションのモニタリングするための鍵は、問題の原因がプログラミング、リソースまたは、その他の原因のいずれかであるかを判別することです。これを把握するには、ユーザーの要求が正しく満たされたことを確認するプロセスが必要です。ユーザーからの要求は、Requestと呼び、このRequestをサーバーで処理し、ユーザーに応答する過程を**トランザクション(Transaction)**と定義します。
トランザクション(Transaction)は、ユーザーのブラウザのリクエストを処理するためのサーバサイドのLUW(Logical Unit of Work) を意味します。 個々のウェブサービス(URL) リクエストの処理プロセスがトランザクションです。 ウェブアプリケーションのトランザクションでは、ウェブサービスのHTTPリクエスト(HTTP Request)を受信し、応答(Response)を返すプロセスです。 WhaTapは、トランザクションの名前をURLとして保存します。 例えば、ブラウザリクエストURLがhttps://www.whatap.io/hr/apply.do?name='kim' の場合、トランザクション名は/hr/apply.do になります。
トランザクションがどれだけ速くエラーなく処理されるかは、サービス応答にエラーなく処理されるかと同じように解釈できます。 トランザクションは、「進行中のトランザクション」と「終了したトランザクション」に分けられます。 「進行中のトランザクション」は、リクエストを送信されたが応答が受信されていない状態を意味し、「終了したトランザクション」は、サービスにリクエストを送信して応答が受信された状態を意味します。 WhaTapのアプリケーションモニタリングは、トランザクションが処理されるプロセスをリアルタイムで確認できるサービスを提供します。
進行中のトランザクション
「進行中のトランザクション」を使用すると、通常8秒以上の遅延を引き起こす問題、広範囲に及ばず、一部のトランザクションのみ発生する問題を特定することができます。次の画面の上部にあるスピードメーターウィジェットでは、現在進行中のトランザクション(中央の領域)と終了したトランザクション(右側の領域)の状況の全体を確認することができます。全体の状況の中で進行中のトランザクションをエージェントごとに表示したのがアクティブトランザクションウィジェットです。進行中のトランザクションの状態を表示したのがアクティブステータスウィジェットです。

トランザクションによって確認できるトラブルの状態は、応答時間を通じて参照できます。 また、進行中のトランザクションが終了しない場合は、これもトラブルとして認識する必要があります。 WhaTapは、進行中の状態の時間に応じて区間を分けて表示します。 青色は応答時間が正常なトランザクション、オレンジ色は応答時間が8秒の遅いトランザクション、赤色は応答時間が通常の2倍以上に遅いトランザクションを意味します。 これにより、ユーザーは直感的にトラブルを認識できます。
アクティブトランザクションウィジェットでは、遅延が発生する状況をエージェント別に確認できます。赤色の領域が各エージェントごとに分散されている場合は、遅延を発生させる要因をエージェントにインストールされたアプリケーションごとに確認する必要があります。逆に、赤色の領域が1つのエージェントのみ発生する場合は、そのアプリケーションサーバーで確認できます。これにより、トラブルの原因が発生した場所をすぐに特定できます。
外部の要素はアクティブステータスウィジェットで確認できます。METHODはその他の事項で通常のトランザクションとみなされます。その他の4つの状態値からトラブルの原因を特定できます。外部接続に関する項目は、HTTPC、SQLの数値です。HTTPCの数値が大きいほど、外部から接続されたサーバーの応答性が低下します。Databaseサーバーへの接続が正しく機能していない場合は、SQLの数値が上がります。
アプリケーションサーバーで最も一般的なトラブルの1つは、DB接続プールに関連しています。DB接続プールの数が不足していると、新しい接続リクエストが発生するたびに遅延が発生し、パフォーマンストラブルの原因となります。この場合、 _アクティブステータス _ウィジェットの _DBC _数値が増加します。
SOCKETは外部システムとのTCP接続の試行を意味します。同様に、SOCKETの数値が持続的に増加する場合は、外部システムへの接続が不足しているためにトラブルが発生している可能性があります。
進行中のトランザクションに問題が発生する場合は、アクティブトランザクションウィジェットのチャートをクリックしてスタックを確認することができます。アクティブトランザクションウィジェットでトラブルが発生した領域のエージェントをクリックすると、エージェントのアクティブトランザクションウィンドウが表示されます。このウィンドウは、進行中のトランザクションの一覧が表示されます。この一覧のトランザクション(URL)またはSQL/HTPC(ms)項目のいずれかが同じかどうかを確認してください。障害の主な原因が同じ現象なのか、それとも他の問題が発生したのかを確認できます。
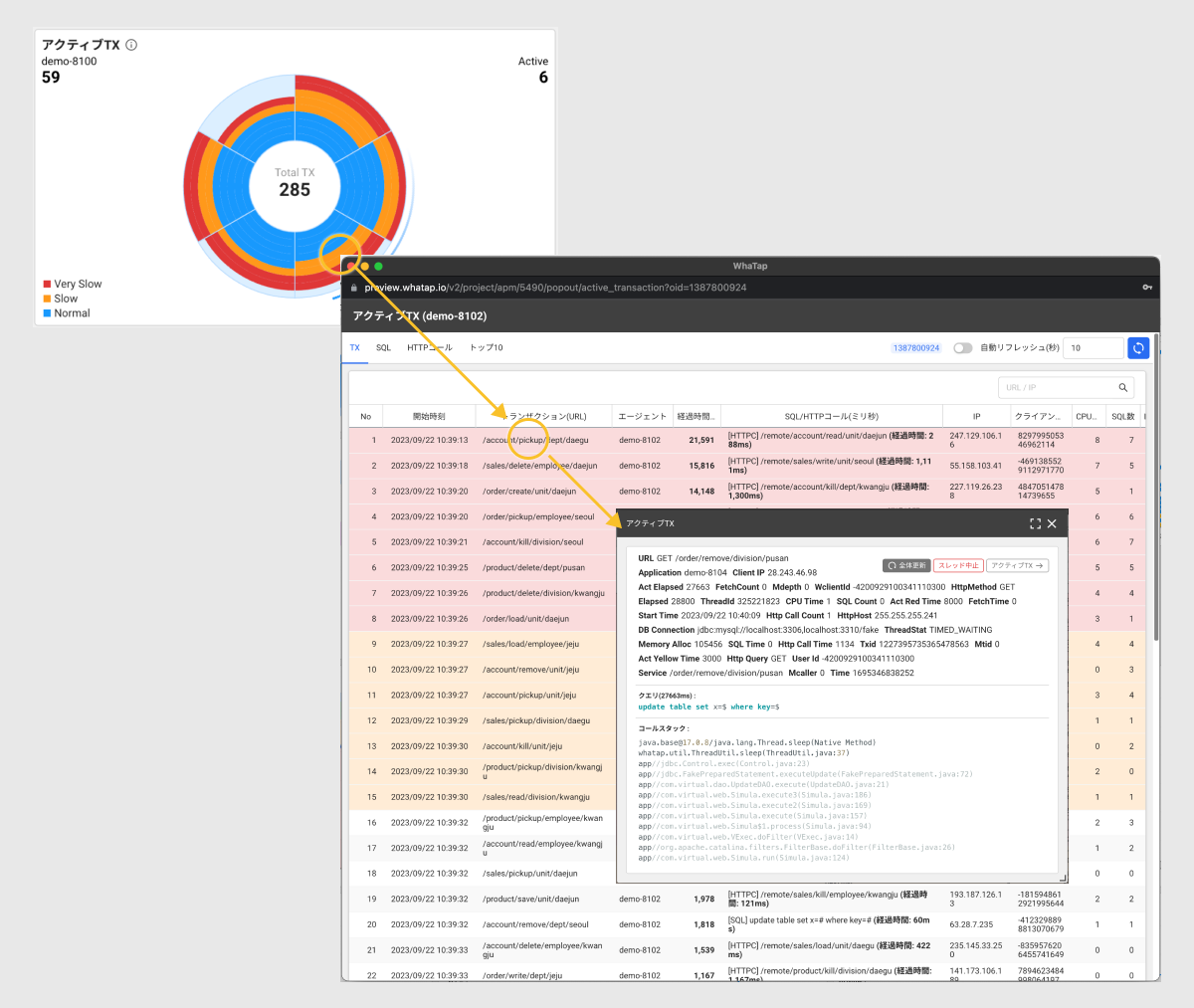
進行中のトランザクションの一覧の項目をクリックすると、それらのトランザクションのスタックを確認できます。このスタック情報からトラブルの原因を分析できます。
終了したトランザクション
終了した個々のトランザクションを分布図として確認できるのがヒットマップウィジェットです。ヒットマップウィジェットは、通常1秒かかるはずのトランザクションが予想よりも2秒程度かかる場合、つまり応答時間が2倍以上かかるトランザクションを見つけることで、トラブルの原因を分析します。
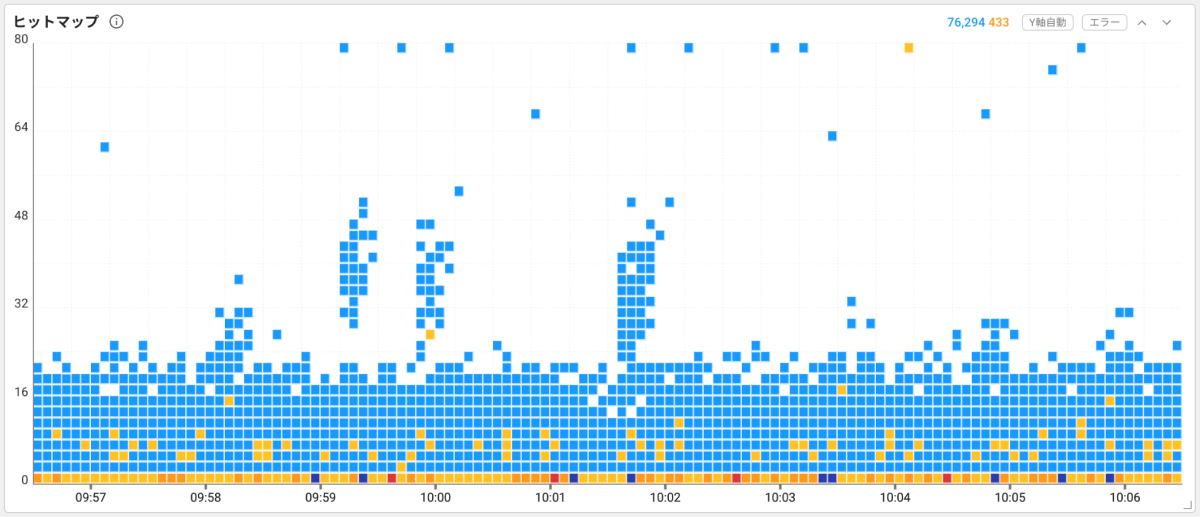
ウィジェットは右上にあります![]() または
または![]() ボタンをクリックするとチャートを拡大または縮小できます。チャート領域をマウスでドラッグすると、トレース分析ウィンドウが表示されます。
ボタンをクリックするとチャートを拡大または縮小できます。チャート領域をマウスでドラッグすると、トレース分析ウィンドウが表示されます。

トレース分析ウィンドウでは、ユーザーがドラッグしたチャート領域のトランザクション情報を一覧で表示します。それぞれのアイテムをクリックすると、そのトランザクションの詳細を右側で確認できます。画面の右側のテーブルビュータブでは、どのプロセスを処理しながら遅くなったのかを段階的に確認することができます。

ユーザーからのリクエストがサーバーに届くまで、サーバーでロジックを実行して結果を表示するまで、多くのメソッドが実行されます。いくつかのメソッドを追跡すれば遅延している箇所を確認できるでしょうか?WhaTapは、複数のユーザーのリクエストを既定の10秒間隔でスナップショットとして保存します。スナップショットに保存されたスタック情報をトランザクションに含めます。この場合のスタック情報をアクティブスタック(Active Stack)と定義します。

トレース分析ウィンドウの詳細については次の文書を参照してください。
スタックを収集し、累積された量を基準に一覧表示して確認できる機能が分析 >スタックです。リソースと関連付けられていない内部ロジックの遅延メソッド間隔を統計的に見つけることができます。

ユーザーおよびサービス、リソース分析
ユーザーとサービス、リソース間の相関関係を分析してAPチューニングを継続するには、ユーザー数に応じたTPS、応答時間、CPU使用率を確認する必要があります。

Transaction Per Second(TPS、以下TPS)は、1秒あたりにトランザクションを処理した量を意味します。ユーザー数が増えると、TPSは次のようにグラフ化されます。

サービスのユーザー数が増え続けると、ある時点からTPSは増加しなくなります。このように増加しないポイントを飽和ポイント(Saturation Point)と呼ばれます。上記のグラフのようなサービスは理想的な状況です。適切にチューニングされていないサービスは、TPSが低下する現象が発生します。
次のグラフを参照してください。 TPSが増加しなくなった状態でユーザー数が増えると、応答時間はユーザーに比例して増加します。

CPU使用率は、ユーザーが増加するにつれて次のようなグラフが表示されます。

TPSの最大値を知るのは難しいですが、CPUの最大値は100%です。ただし、CPU使用率が100%または100%に近い場合でも、CPU使用率だけではリソースが不足しているかどうかを判断するのは困難です。これは、サービスのロジックに問題があり、CPU使用率が高くなる可能性もあるからです。そのため、上記の3つのグラフを直観的に把握し、比較して判断することが重要です。
TPSはパフォーマンスのベンチマークです。つまり、最大TPSは、システムの最大パフォーマンスを意味します。最適なチューニングは、最大TPS値を上げることです。
応答時間は、ユーザー数が増えるとそれに比例して増加するため、チューニングの指標として使用することは困難です。ただし、応答時間が緩やかなグラフであることが重要です。最大TPSを増やすには、応答時間のグラフを緩やかにする必要があります。したがって、チューニングの対象は応答時間です。個別URL、つまりトランザクションの応答時間を特定して分析することが必要です。ヒットマップを使用すると、トランザクションの応答時間を分析し、遅くなる間隔を見つけて原因を特定することができます。
上記の概念を熟知した状態で、アプリケーションダッシュボードのTPSウィジェットとユーザーまたは同時接続ユーザーウィジェットを確認ください。ユーザー数が増加し、TPS数が減少する場合、サーバーへのトラフィックが増えることを意味します。この場合、Scale-Outによってサーバーリソースを増やすか、トラフィックを制御してTPS数を一定に保つことをお勧めします。

Scale-Outする場合でもモニタリングできるようにWhaTapのエージェントを追加する必要があります。Traffic制御が必要な場合は、WhaTapのエージェント設定で対応可能です。アプリケーションの最大同時処理数を制限できるスロットリング機能を活性化できます。詳細な設定方法については、次の文書を参照にしてください。
また、次のグラフのようにユーザー数は増えても、TPS数が最大に増加せずに一定の場合、2つの状況が考えられます。グラフResponse#1のように応答時間が継続的に増加している場合は、サービスロジックに問題がある可能性があります。一方、グラフResponse#2のように応答時間が一定の場合は、ユーザーのリクエストをサーバーが受信していない状況でネットワークの状態を確認する必要があります。

さらに、ウェブアプリケーションの顧客満足度を測定するApdexウィジェット、ヒープメモリウィジェットを確認することができます。
Application Performance Index(Apdex)は、アプリケーションのパフォーマンス指標です。
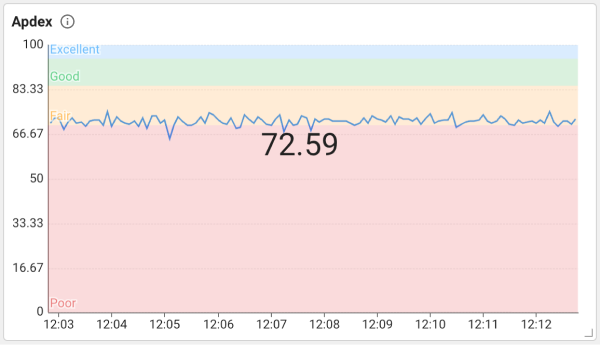
ユーザー満足度の指標として使用され、0~1の値を持ちます。0~0.7はPoor(赤色)、0.7~0.85はFair(オレンジ色)、0.85~0.95はGood(緑色)、0.95~1はExcellent(青色)の領域で表示します。Apdex指標とカラー領域のアプリケーションの応答速度がユーザーに満足できる水準であるかを確認できます。Apdex指標の詳細は次の文書を参照にしてください。
ヒープメモリー(Heap Memory)ウィジェットは、各サーバーの使用可能な最大メモリーと現在使用中のメモリーを表示します。
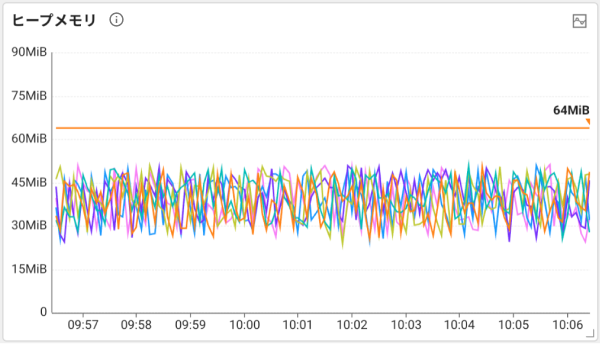
Heap使用量が低い場合、GCが頻繁に発生し、CPUが過剰に占有されます。通常のHeap使用量パターンはGCによって上下を繰り返します。ヒープメモリチャート分析の詳細については、次のリンクを参照してください。
- 月間WhaTap:モニタリングで注目すべき指標(韓国語)
- Javaヒープメモリーチャートの分析:Ch.1ヒープチャート観察
- JAVAヒープメモリーチャートの分析:Ch.2 メモリリークとヒープダンプ分析
統合ダッシュボードを提供する可視性の高いモニタリングサービスであるWhaTapを使用して、モニタリング業務の効率を高めてみてください。